Training Generative Adversarial Networks with Limited Data
Section 1. Introduction
目前来说想要训练一个高质量的GAN需要的数据量是非常大的,尽管网络上有看似无穷无尽的图像数据可以获取,但是大多数由于客观类别、图像质量、地址位置、时间段、隐私和版权等各种问题,在一个问题上训练一个modern、high-quality的GAN模型存在较大的困难。
传统方案是使用数据增强,比如使用旋转、噪声等方法。这种数据扩充的方法增强了图像的保留语义失真(换个说法,简单解释,图像语义是指这个图像到底展示了什么,语义失真的程度表明了这张图像能被认为是原始清晰图像展示的内容的程度),这对分类器来说是一个很好的特性。但是对GAN来说,情况就不是这么样了,多数情况下GAN会学习整个图像的数据分布,加噪声增强,那么学到的分布就带有噪声(尽管本身数据集并不包含有噪声)。
本文展示了一种使用数据增强的方法来避免判别器过拟合的技术,并保证不会出现上述问题(即上面的例子,加噪声会导致学到噪声分布)。文章将进行全面的分析然后设计一个多样的增强方案和自适应控制方案来解决少量数据训练GAN的问题。在数个数据集上,我们展示了仅使用几千张数据数据就可以得到一个很好的结果。一般的来看,使用少一个数量级的图像就可以撇皮StyleGAN2的结果。类似的在CIFAR-10上,取得了FID=2.42;
Section 2. Overfitting in GANs
为了探究不同数量集的数据集对于GAN图像生成质量的影响,我们对FFHQ和LSUN CAT两个数据集进行了子集采样。为了对照试验,实验中使用了256大小的数据输入,这样使用NVIDIA DGX-1比用原始大小的FFHQ快了4.6倍。最后在50k张生成图像和训练图像数据上计算FID来进行评估。
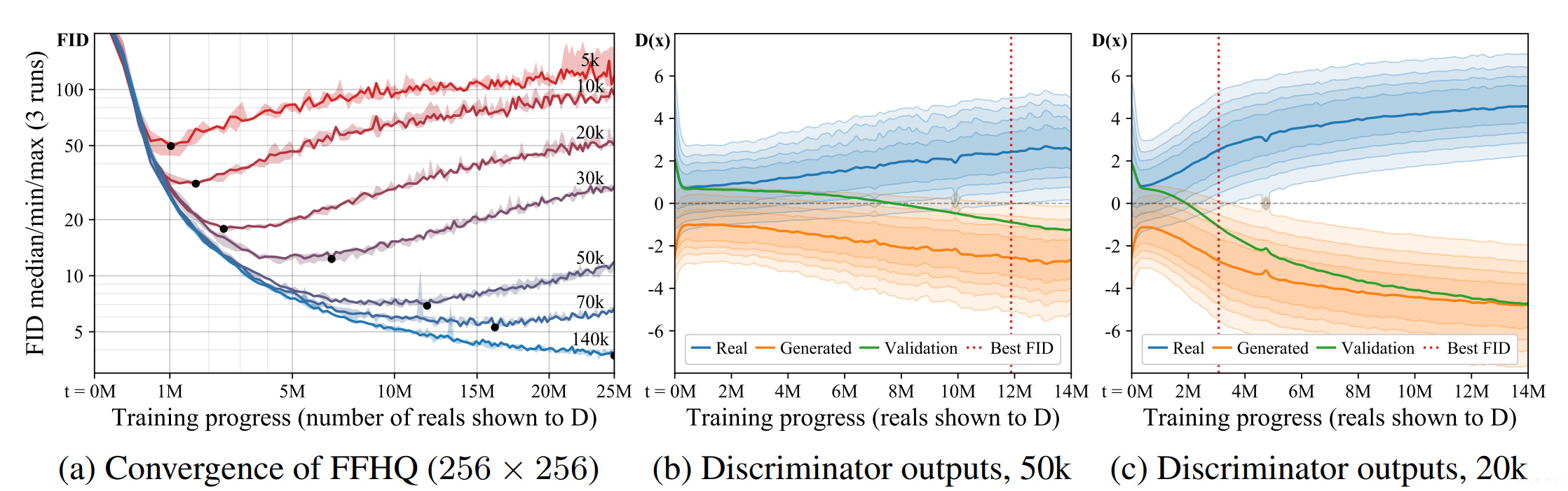
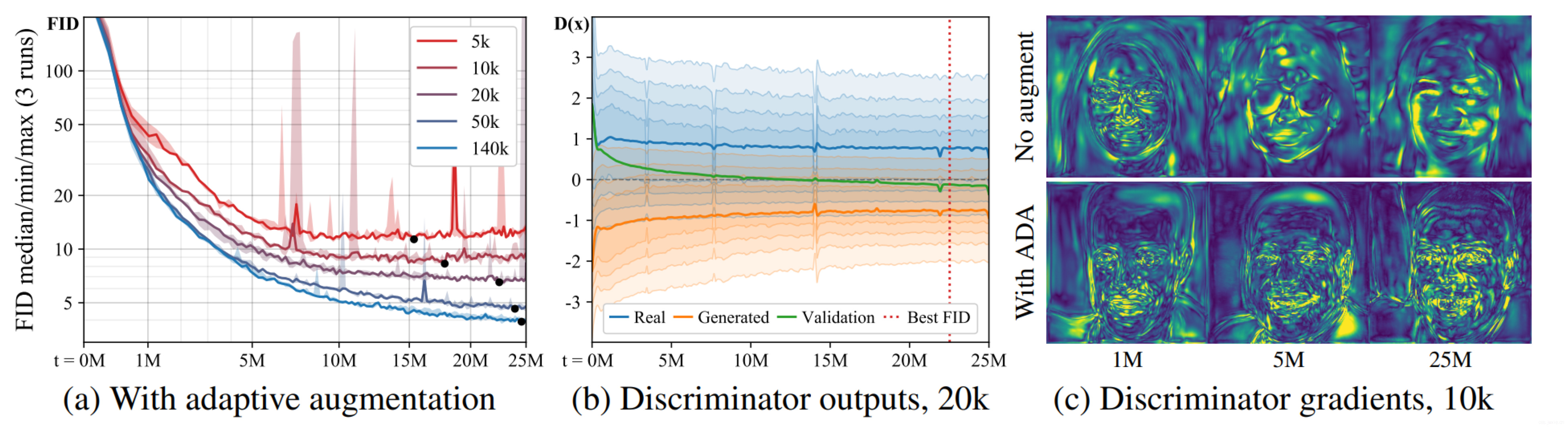
上图(a)展示了FFHQ数据集上的baseline,基本每个实验都是相同的开始,最终FID缓缓提升结尾。在整个训练过程种,**数据量越小,缓缓提升的时间越早。**b,c展示了判别器在训练截断对real和fake图像的输出分布。一开始是重叠的后面开始约分越开(判别器overly confident,模型过拟合),而这个开始分开的过程与FID提升的时间点是同步的。
2.1 Stochastic discriminator augmentation
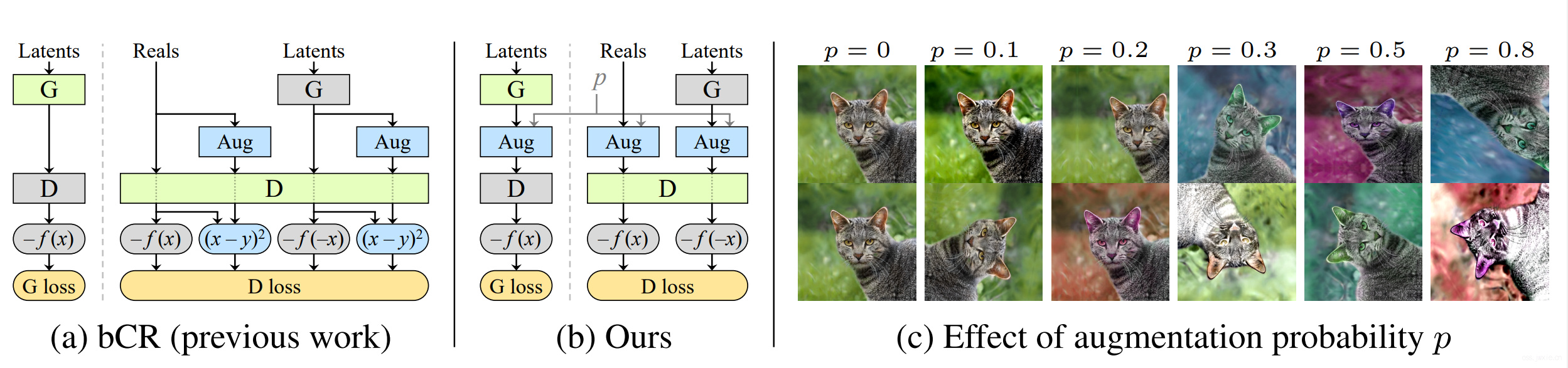
从理论上说,任何应用在训练集上得数据增强都会促使整个生成器的生成分布偏向增强的分布。bCR提出了一个解决方案来避免这种情况,bCR本质上是通过:同一张输入数据,两组增强的结果应该是一致的来进行设计的,从而将一致性损失加入到判别器中,保证输出输出的一致性,针对生成器则不采用一致性损失。
总的来说就是让判别器别管增强的结果,在这个前提下来对生成器进行一定的训练引导。
本文提出的方法和bCR是类似的,只不过本文的所有输入都是经过增强过后的,不添加CR损失,同时确保在生成器训练的过程中也进行增强,起个名字叫随机判别器增强(Stochastic Discriminator Augmentation)。乍一看,没区别啊,所以首先我们需要看看什么情况下将增强的数据分布暴露给生成器。
2.2 Designing augmentations that do not leak
本质上增强的目的就只有一个:给判别器加个图片(可能是扭曲甚至是破坏性的)滤镜,要求生成器其生成一些即使经过滤镜之后仍不能与训练集区分的数据。
以前GAN要求生成器生成fake数据要像真的一样,现在加一些要求,保证生成的数据即使进行增强后要与训练集不一样,同时分布也不能歪到增强的地方去,总而言之就是在有限的数据下尽可能去还原真实分布。
有论文指出,只要这个增强是可逆的,那么这种增强操作就是non-leaking的(即不会将生成分布暴露给生成器)。这里可逆的意义在于,通过观察增强后的数据**是否可以反演出原始数据,这个和是否可以撤销是不一致的,**比如把90的图像数据置零,在概率分布意义上是可逆的,即使对人类而言,根据10%的图像也可以推断出一定的原始分布;而在0,90,180,270度之间随机的旋转是不可逆的,因为没办法去判断增强前后的差异。
然而,这个情况是可以被缓解。当我们对数据做增强,确保增强的比例小于1,也就是增加的旋转0°的样本,这使得只有当生成的图像具有正确的方向是才能匹配分布。附录C里展示了这个思路是广泛有效的。同时,按固定的顺序进行non-leaking的增强的累加,总体产生的结果也是non-leaking的。
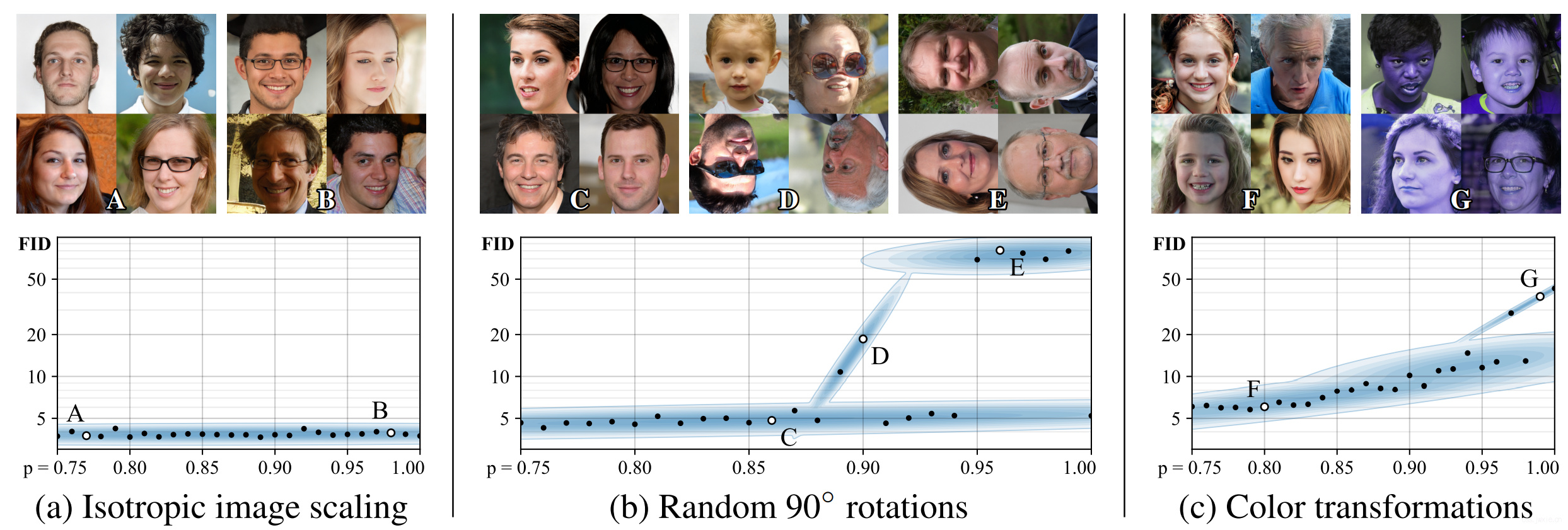
为了我们在上图验证了一下想法,对数正态分布(❓)的下的各向同性缩放是安全增强,不管p是多少都可逆。如上所述90度的旋转并不是一直安全,当旋转角度太高,生成器就不知道哪个是正确的方向了。实践中,由于各种因素的干扰,p大约保持在0.8时是有效的,虽然一开始会错,但是最终会朝着正确的方向优化。类似的结果也出现在颜色增强上。总而言之一句话,\(p<0.8\)情况下大多数增强都是安全的。
2.3 Our augmentation pipeline
假设大规模和多样性的增强在GAN的训练中是有意义的(因为,分类问题上的确是这样)。考虑6类18种变换方式,详见附录B。有一点要求,增强针对生成器也是存在的,因此需要增强方法是可微分。在训练的时候,以一个预定义的顺序给判别器输入图像数据,控制概率p在0-1之间。同时确保对同一张图像所有的transforms都应用同一个p值,随机的点落在每一个minibatch中的不同的图像之间以及每一个数据增强方法之间(❓)。
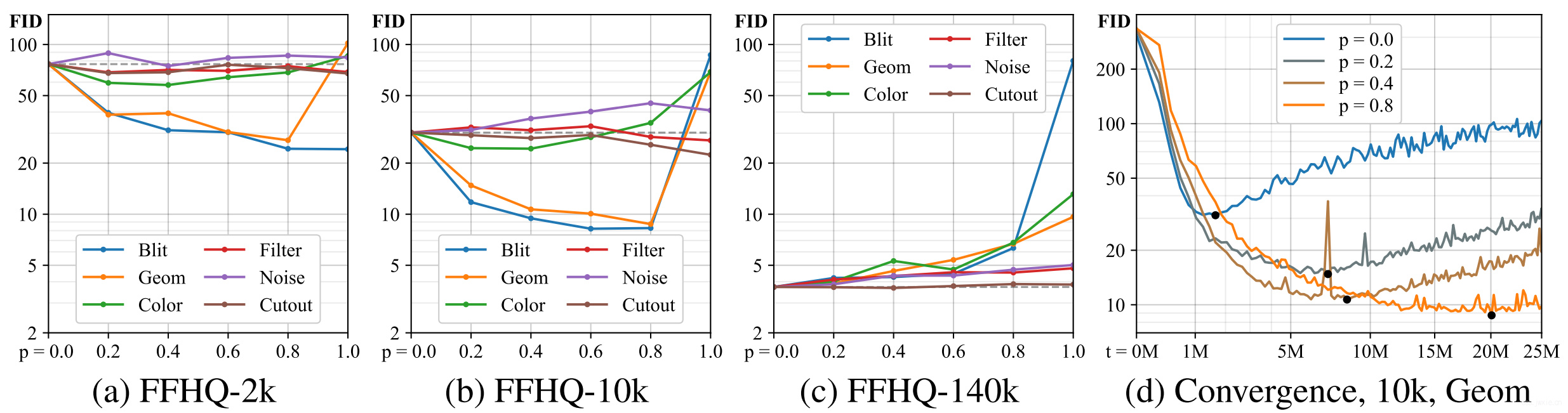
上图可以看出,在2k数据的情况下,主要的增强收益来源于pixel blitting以及geometric transfroms,color transfroms次之,最后是image-space filtering,noise,和cutout不佳。同时,可以发现施加较大概率的增强能取得较好的结果。上图b,c展示了随着数据量增大,p并不是越大越好。图d则表明了越多的数据增强会导致收敛变慢。
Section 3. Adaptive discriminator augmentation
理想上来说,最好是可以网络根据过拟合的程度自由进行p值调整。常规的方式就是使用独立验证集,但是问题是本身数据量不足的情况下,训练数据是非常宝贵的。针对图1我们可以注意到,使用非饱和loss,随着过拟合的症状加深,real和fake图像的判别器输出以0为界限,对称发散(可以利用这一点来进行判断过拟合程度)。 $$ r_{v}=\frac{\mathbb{E}\left[D_{\text {train }}\right]-\mathbb{E}\left[D_{\text {validation }}\right]}{\mathbb{E}\left[D_{\text {train }}\right]-\mathbb{E}\left[D_{\text {generated }}\right]} \quad r_{t}=\mathbb{E}\left[\operatorname{sign}\left(D_{\text {train }}\right)\right] $$ 针对上面这个思路,\(D_{train}\),\(D_{validation}\),\(D_{generated}\)是训练、验证测试集中的图像的判别器输出,\(\mathbb{E}\)表示对\(N\)个minibatch的判别器输出值的期望,这里\(N=4\),也就是256张数据(batch=64),即可以生成过拟合程度系数\(r_{t}\)。接下来,也就是说我们只要控制p与过拟合成都系数就行了。左边的式子,很直观的理解就是训练集和验证集的判别器的输出的期望差,与训练集和生成图像在判别器上的数据的比值。由于需要独立验证集,这里主要把这个方法作为一个对比。右边那个式子,\(r_t\)估计了判别器获得正输出的比例。
个人理解,\(r_v\)应该是越靠近1越好,\(r_t\)应该越小越好
也因此我们就可以对\(p\)的强度进行一些自动化的调整,在一开始设为0,然后按照上面所说的启发式构想, 每4个minibatch进行一次调整,调整的方向就是much/little过拟合<–>incrementing/decrementing \(p\)值。
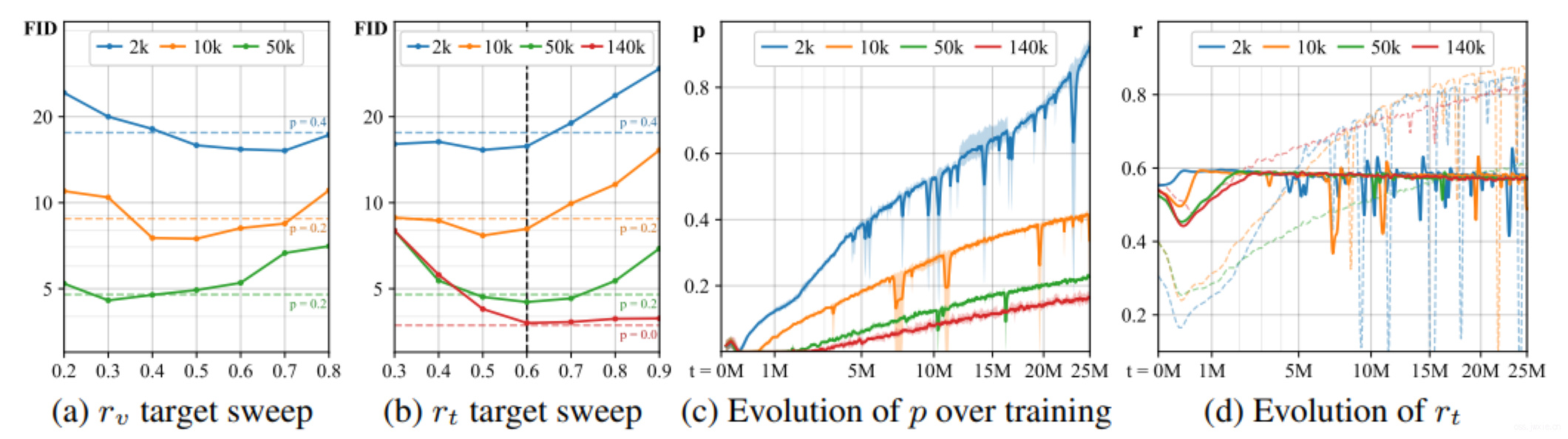
在上图中a,b中,评估了之前的两个方式对最后的FID分数的影响,后续的实验中会采用第二种方式(作者任认为更realistic),也就是\(r_t\),target_value设置为0.6。c表明了随着训练时间增长,\(p\)的强度会越来越大。也别是在2k数据的情况下,一旦超过0.6数据增强就开始显得有些leaky了。在这个极端的情况下,FID在随着\(p\)的增长大约是在\(p≈0.5\)后开始恶化。图d显示了在固定\(p\)(实色线)和变化\(p\)(虚色线)的过程中\(r_t\)大的变化,当固定\(p\)的时候\(r_t\)在开始时震荡强烈,在结束时变化微弱。
这里target_value就是best fixed augmentation probability,即最合适的增强比例
Section 4. Evaluation
在两个数据集(FFHQ, LSUN CAT)上进行了评估,两种方式从头训练和预训练模型。
4.1 Training from scratch
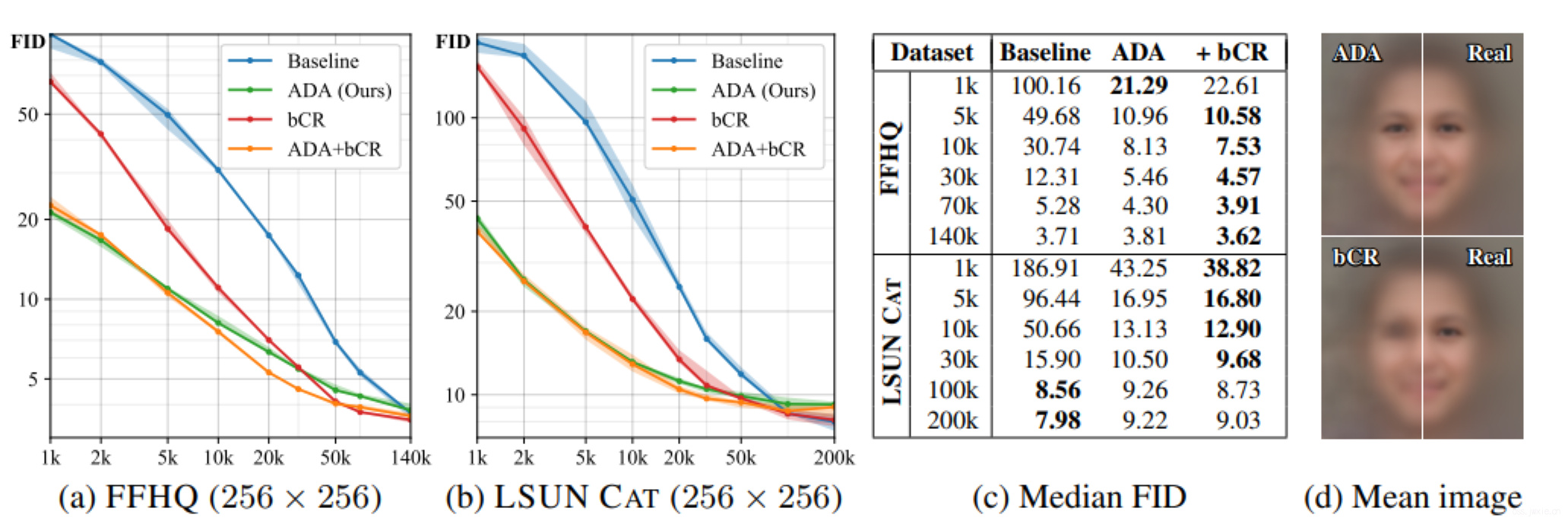
上图a,b,c展示的结果很好的展现了ADA能很好地帮助训练,特比看bCR的确有效但是也有限制就是数据缺失不能太严重,图d则进一步表明了bCR存在leak导致了模糊(❓)。
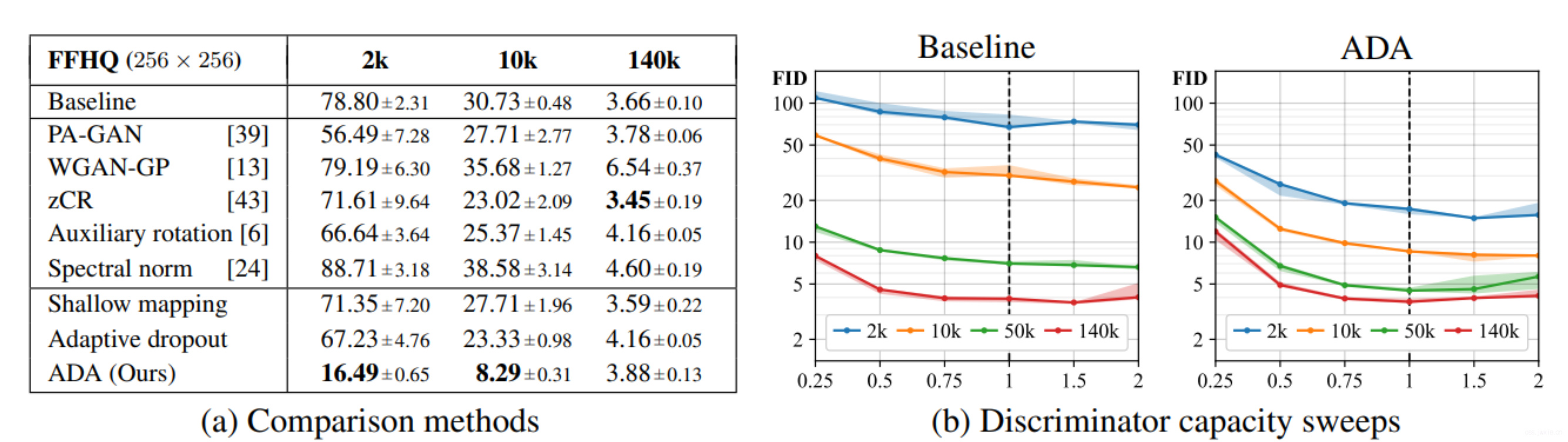
上图a没啥好讲的,主要就是说了一下对比试验,同时指出虽然PA-GAN和ADA很类似但是就是不太行。上图b纵坐标表示FID评估指标值,横坐标是对判别器里的特征层的特征层的值进行缩放的比例(表示对判别器进行“削弱”)。表明通过削弱判别器对最终的结果是无效的。
感觉这里的描述有那么一点点的敷衍,直接对判别器的特征图的值进行scale就能表明削弱判别器嘛 0.0
4.2 Transfer learning
这里讲到了一个技巧就是Freeze-D(感觉找到下一篇博客的方向了: -) ),就是在进行迁移学习的时候冻结判别器的最高分辨率的一层。作者这里还讲了实际上迁移学习的效果主要来源于源数据集的多样性,比如FFHQ能从CeleBA-HQ(低多样性)以及LSUN-DOG(高多样性)模型之间进行训练,但是LSUN-CAT只能从LSUN-DOG里面进行预训练。
上面这个还是挺有意思的。
4.3 Small datasets
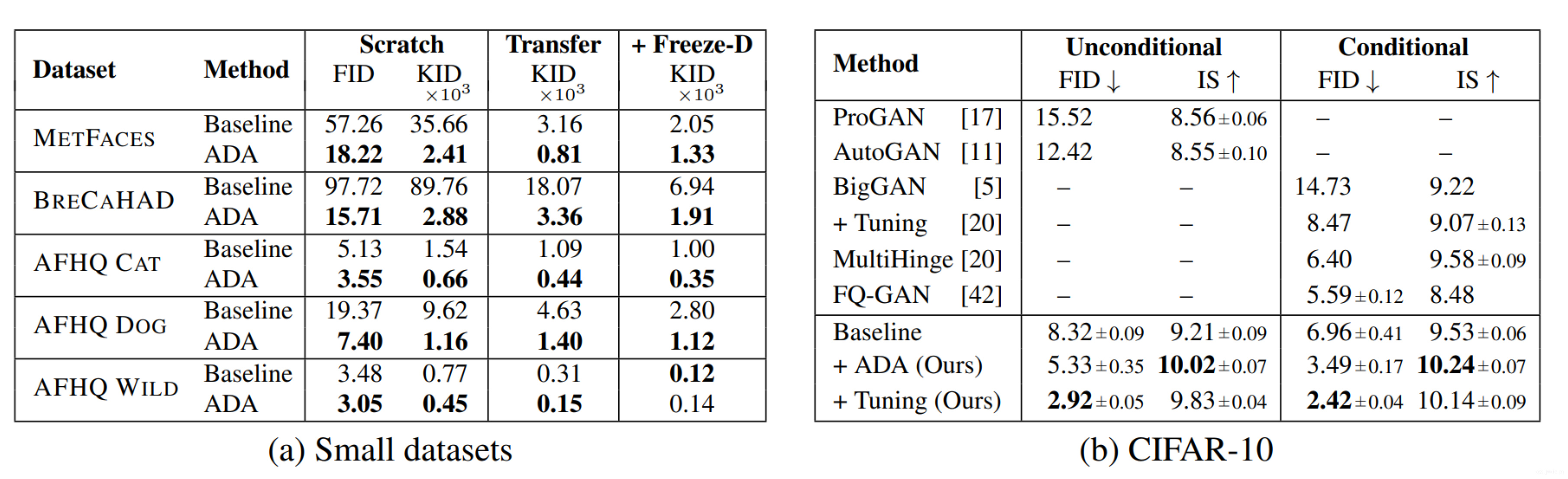
测了一下小数据集上的效果如下两张表所示。
Section 5 Conclusion
没啥好讲的,就是总结嘛。 😄
Border impact
- 介绍了数据和模型训练之间的相关性。
- 不引用新功能但是提升了训练效率。
- 不会对模型的结果产生影响。
- 能让人们更好的训练高质量的生成模型,增强了应用场景。
等等…