RepVGG: Making VGG-style ConvNets Great Again
Section 1 介绍
卷积网络最近成为了很多任务的主流解决方案。近期许多团队都开始专注更复杂、更精巧的网络结构设计如ResNet、DesNet等,甚至是使用NAS等自动结构搜索来进行网络设计。但是这类模型存在着一些缺陷:
- 多分支的设计使得模型的实现落地和客制化变得困难,同时减慢了推理时间,并增加了内存占用。
- 一些流行的操作虽然可以获得不错的准确率,但是这些操作显著增加了内存(显存)读取成本(Memory Access Cost,MAC),如depthwise卷积或者通道shuffle。此外这些操作还增加了在各个不同的设备上落地的难度。
- 大多数论文都以FLOPs来作为减少计算量的标准,但是FLOPs并不代表运算速度正相关(涉及到计算密度、MAC等操作都会影响推理时间)。
因此本文提出了RepVGG,主要有以下几个优点:
-
RepVGG(在推理时)是一种plain形式的模型(上一层输出为下一层输入,没有skip等分支操作)。
-
只使用了3x3的卷积以及ReLU,这个可以便于定制硬件加速器。
-
模型没有用到NAS,精巧的手工设计,compound scaling(EfficientNet里的那个)以及其他任何的一些繁重的结构设计。
虽然使用plain的模型有很多有点,但是就是性能差。之所以多分支结构性能强劲的一个原因是多分支本质上是一种框架结构的解耦,这种解耦后的多个子模型的集成能获得更好的效果。
既然多分支那么有效,那么我们依然使用这种多分枝的结构来进行训练,而在测试阶段,我们可以尝试讲这几个分支整合起来,变成一个plain的结构,如下图所示。
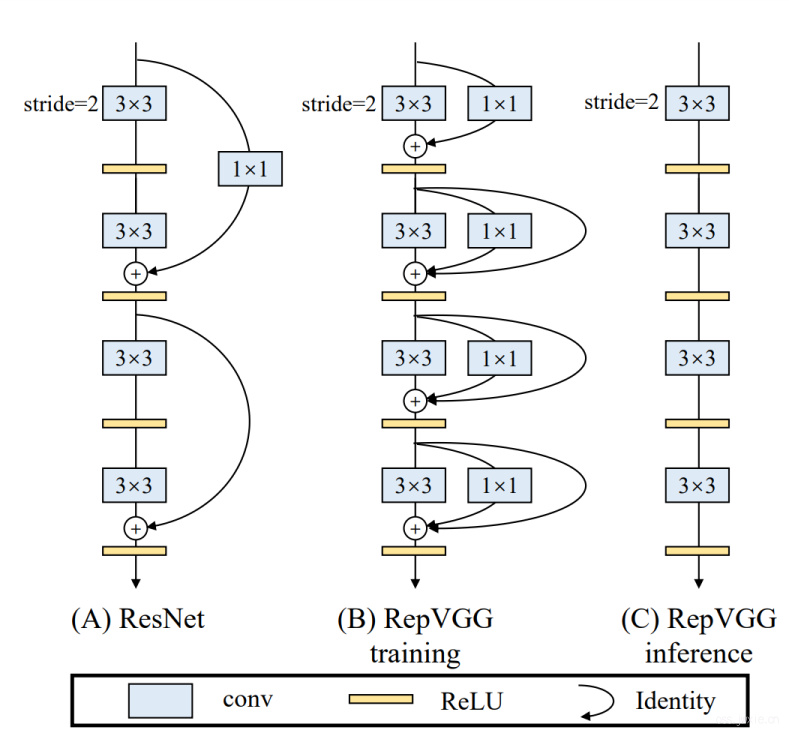
具体的呢,就是在训练时间使用了一个1x1的卷积和一个skip连接(这个是学ResNet的)。但是与ResNet不一样的是我们在每一个卷积上都用了这种形式,且每一个分支都有一个自己独立的BN,而且在测试阶段我们把这个多分枝的结构整合成了一个3x3的卷积(通过structure re-parameterization)。因此,总体来看RepVGG的推理时间只与3x3的卷积以及ReLU的计算时间相关。
本文的贡献:
- 提出了RepVGG,一个有效的speed-accuracy tradeoff的模型。
- 提出了一个有效的结构重构方法,使得解耦训练过程中的多分支,使之在推理阶段成为一个plain的模型(加速计算)。
- 展示了RepVGG在图像分类以及语义分割领域内的优势以及实现和部署的高效性。
Section 2 相关工作
2.1 From Single-path to Multi-branch
随着VGG取得了70%以上的准确率,许多团队尝试探究了复杂的网络结构设计。比如GooLeNet、ResNet、DenseNet之类的,NAS以及搜索空间设计的方案可以生成一个高性能的模型,但是随之而来的一个问题是这类NAS-generated模型甚至无法在常规GPU上进行训练,因此限制了实用性。
2.2 Effective Training of Single-path Models
事实上还是有许多工作在尝试使用plain形式的模型来进行探索。但是文前的许多工作都在尝试着探索如何把网络加深(避免过拟合、提升准确率),因此这类网络也并不是很可行。
注意的是本文并不是单纯的展示plain模型可以更好的拟合,或者说训练一个超级深的网络结构。文章旨在使用一些常见模块在组件和算法一个介于精度-速度的平衡点的模型。
2.3 Model Re-parameterization
DiracNet 是一个re-parameterization的一个案例模型,与文章的想法相似。DiracNet通过对卷积核的参数进行了重构: $$ \hat{\mathrm{W}}=\operatorname{diag}(\mathbf{a}) \mathrm{I}+\operatorname{diag}(\mathbf{b}) \mathrm{W}_{\text {norm }} $$ 具体的细节可以查阅论文,该方法的问题在于性能对比ResNet有所降低了。
Asym Conv Block (ACB)采用了非对称卷积来加强常规卷积的结构,它将训练好的一个块转换为一个卷积。因此可以被看作为一个另一种形式的结构re-parameterization。RepVGG与之不一致的地方在于ACB是组件层面的实现,可以在任何网络中代替卷积。RepVGG则是使用一个多分支的结构来训练plain模型。
2.4 Winograd Convolution
3x3的卷积的理论计算密度是其他的1x1、5x5、7x7卷积的四倍左右,如下表。目前3x3卷积的加速可以使用Winograd卷积,这个在cuDNN以及MKL库中都默认支持。

Section 3 方法
3.1 Simple is Fast, Memory-economical, Flexible
为什么要使用更简单的卷积网络有许多理由:
-
Fast,许多多分支的结构有着币VGG更低的理论FLOPs,但是并不见得比VGG快多少。排除Winograd卷积带来的优化,FLOPs与实际运算速度的差异主要源自于MAC以及并行化程度的差异。尽管加和拼接在计算上占用的时间几乎可以忽略,但是MAC不能被忽略,尤其是在groupwise卷积上,这点更甚。此外,并行化程度也是评估一个网络计算速度的重要因素。实质上在一个网络中包含太多的切分计算会大幅度降低模型的并行化能力。例如某一个NASNET-A是13,而与之对比ResNets为2-3。
-
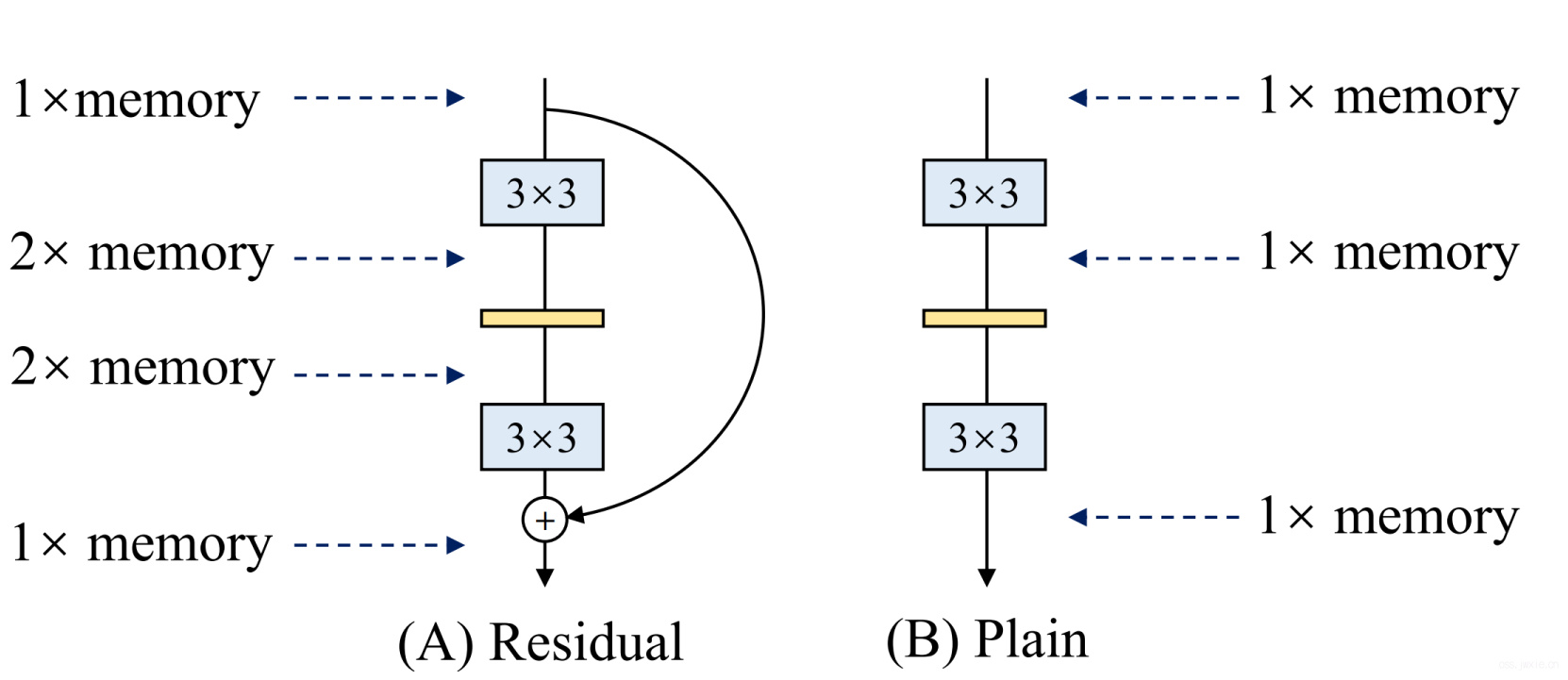
Memory-economical
多分支的结构本身本身是不利于内存(显存)占用的,因为每一个block的计算结果都要保存,直至addition或者concatenation。如下图所示:
-
Flexible
多分支的结构实质上对结构是有一定的约束性的,因为在addition或者concatenation的时候必须保证前后两个拼接的张量是同样大小。而且多分支的这种结构对模型的剪枝也是有一定的限制性。
3.2 Training-time Multi-branch Architecture
plain模型有好多有点,但就是一个巨大的缺点就是性能差。文章提出的结构实际上和ResNet有些些的类似,即\(y=g(x)+f(x)\),\(g\)实际上是一个1x1的卷积。此外还额外增加了一个identity,最终变成\(y=x+g(x)+f(x)\)的形式。
整合起来看,实际上就是有一堆上面那种形式的子结构的堆叠,堆了n次,一共\(3^n\)个子模块。
3.3 Re-param for Plain Inference-time Model
😂这部分的公式我就不细写了,有兴趣的可以去原文看看,就是一些比较常规的卷积计算公式之类的,还有一些如何把卷积和BN叠在一起的公式。
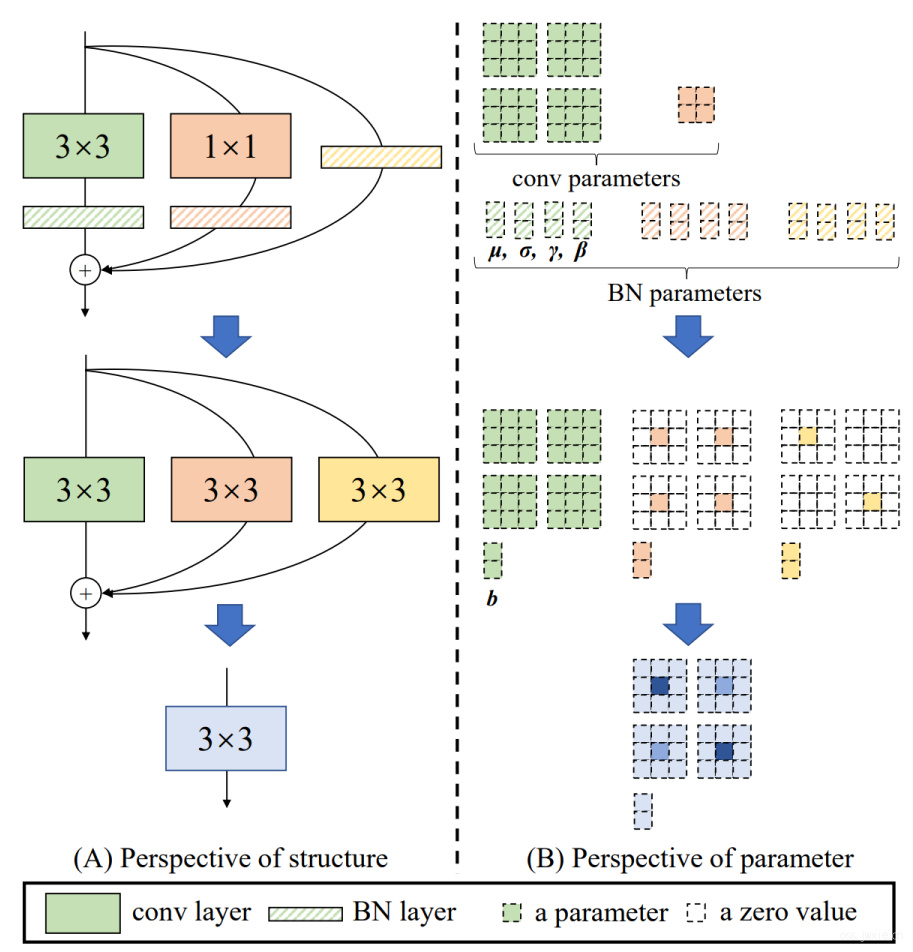
这个章节主要是介绍如何把刚刚所描述的那个在训练阶段的\(y=x+g(x)+f(x)\)在测试阶段整合为一个3x3的卷积。
具体如下图所示。在训练阶段假定输入输出的channel都是2:
- 那么一个常规的3x3卷积实际上含有3x3x4的参数量,带上一个BN,再加4个参数。
- 此外,可以注意到的是1x1的卷积实际上就一个带了好多0的3x3卷积,带上一个BN,再加4个参数。
- 最后identity映射实际上就是一个单位阵,也可以把他看作为一个很多0的3x3矩阵,再带上一个BN,加4个参数。
此外常规的卷积网络在部署的时候常会吧卷积和BN叠在一起算可以加速[1],这里也这么做一下,就变成了下图第二行所展示的那样。
最后做一个线性整合,最后的到一个3x3卷积以及一个BN的参数,这就实现了下图第三行所示的单路模型结果。
3.4 Architectural Specification
下表展示了RepVGG的具体构成,包含了深度和宽度。网络中5个stages,只含有一些纯粹简单的3x3卷积和直线形式的那种拓扑结构。此外,RepVGG里不包含任何的池化操作。

当然,文章在这个基础上对网络结构做出了一些深化,具体的就是每个stage的卷积数量变多了一些(头尾不变)。
Section 4 实验
这部分不讲了,关注的可以看看论文,比较重要的也就是对比试验的结果以及消融试验等一些结果和分析会比较有意思。此外,重要的一点就是RepVGG应该是第一个基础模型拥有80%+准确率的模型。
Section 5 局限性
RepVGG是为最小化GPU和专用硬件上卷积网络运算时间的而设计的,尽管RepVGG比ResNet有更少的参数但是,但是在一些低算力的设备上,效果可能比不上MobileNet和ShuffleNet系列。