Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Section 1 介绍
近些日子,GAN在图像生成领域(尤其是人脸图像)取得了较大的进展。比如说StyleGAN就通过MLP实现了一个从离散的潜空间到人脸图像的可控、可编辑的人脸生成器。
近些日子也又不少人尝试去进一步的探索了人脸编辑,但是很多情况下,我们需要把图像转换为潜空间里的向量,然后再通过styleGAN来实现重建。很多时候,这个重建的结果不是太理想,而且也很费时间(存在优化过程,不是单纯的端到端)。为了实现端到端的方式,也有工作尝试过加一个encoder来实现近似编码[1, 2],但是这一样需要额外的优化❓。
本文尝试了一个更宽泛的潜空间编码,目的并非是单纯的对输入1:1地编码到潜空间,而是按照我们的想法来进行这个过程。encoder基于FPN,因此每一个style都抽取自不同的金字塔的层级,然后塞到预训练的styleGAN里。这个过程我们称为pixel2style2pixel,可以用来解决很多人脸相关的问题。
许多前人的工作在针对image2image的任务都涉及了独立的、专用的结构,我们这里选择不这么搞,想法是整一个更general的框架。而且很多之前的方法都是直接拿了残差模块后输出的特征来塞到styleGAN里,这造成了很大的定位偏差(locality bias)。我们的方案是直接把styles送到styleGAN里去而不加入其他的spatial输入。这个方法尤其在人脸正面化方面取得了较大的优势,可以完全以无监督的方式来进行。其次是对中间style表征的支持使得我们可以用于许多人脸相关的任务,比如超分、分割图人脸生成等。
创新点:
- 一个能直接编码真实图像到潜空间的的styleGAN编码器。
- 一个通用的解决image2image的端到端框架。
Section 2 相关工作
Latent Space Embedding
GAN invertsion近些日子取得了比较大的关注。但总的来看,一般要么是直接去优化输入变量,要么是训练一个encoder来进行编码,又或是用一个超参数对编码进行融合。总的来看,基于优化的方法一般能取得比较好的性能,但是费老大劲了(费时、费计算量)。老哥[3]尝试训了一个encoder来infer编码向量,保证人脸是一个人的前提下,融合另一张图像中人脸的光照、表情和姿态。但是这个项目也是属于task sepcific的,不是那么的general。
Image-to-Image
自从Isola老哥使用条件GAN来解决多样的图像翻译任务,许多人对他的工作进行了拓展,比如高分辨率乳香生成、无监督学习、多模态图像生成、跨领域图像生成以及条件图像生成。
前面那些工作都用到了一些特定的结果不通用,而且我们直接用了预训练的styleGAN,更便于训练、使用。
Latent-Space Manipulation
利用潜变量来进行人脸编辑得益于GAN的高精度人脸生成以及在编码层面的语义级修改,使得我们并不需要对生成器进行大规模的训练。
基本上大多数都是采用了invert+edit的方案。然后也因此产生了一堆编码生成的方案。比如找到一个线性的编辑方向来修正表情;利用预训练的3DMM在潜空间中学习语义进行人脸编辑;以自监督的方式(通过对图像旋转和缩放)找到对应于特定图像变换在潜空间里的编码的编辑路径;通过对中间激活空间使用PCA,以完全无监督的方式找到合理的编辑方向;学习潜空间编码向量之间的转换,从而修改一组预定的标签属性;通过操作潜编码的相应分量,进行局部语义编辑。
几个局限在于,输入的数据必须得是可逆的才行,也就是说潜编码必须存在才行。但是,也是可以解决的,比如扩大优化空间。但是这个方法也是有缺陷的,通常来说会对陌生数据缺少一些丰富的细粒度特征。其次,可逆的这个过程依旧是比较困难的。
因此,俺们提出了pSp!
Section 3 pSp结构
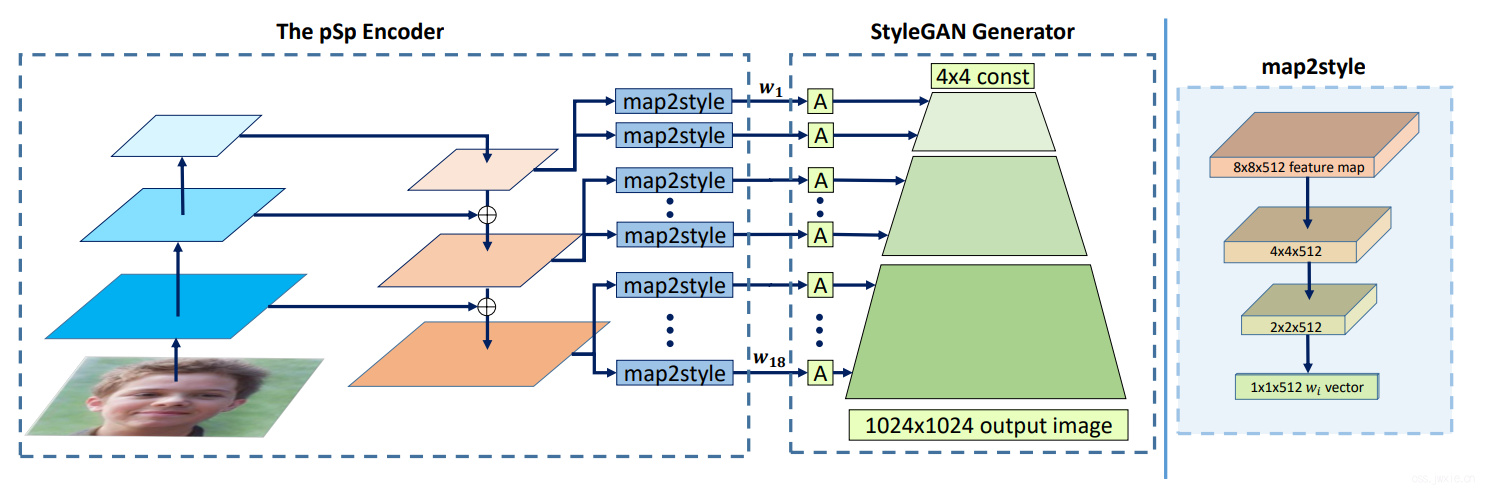 传统而直接的方案是直接使用编码器最后一层的512维向量来然后repeat18次,但是问题是这个编码生成地很随意,表征不够丰富(大方向上可以保证一致,但是会缺少细节)。
传统而直接的方案是直接使用编码器最后一层的512维向量来然后repeat18次,但是问题是这个编码生成地很随意,表征不够丰富(大方向上可以保证一致,但是会缺少细节)。
styleGAN的作者提出了不同的level的编码实际上代表了不同层次的特征,大致可以分为三组coarse、medium和fine。因此,我们使用FPN来实现这个encoder,也生成三种不同level的特征。然后利用一些简单的全连接(map2style模块)来生成18个编码。
当然作者也试了试一些其他的思路(虽然采取了FPN的思路)也有效,比如直接从最大的特征图里生成所有的style编码可以取得相似的效果,但是会影响模型大小。另一个极端是从最小的特征图生成所有的编码,在保证维度足够的情况下也能保证性能稳定。
3.1 Loss Functions
尽管基于style的图片翻译是模型的核心,但是损失函数的选择依旧是很关键滴,文章选了一个加权整合了多个损失函数。首先第一个关键是\(\mathcal{L}_{2}\)损失: $$ \mathcal{L}_{2}(\mathbf{x})=|\mathbf{x}-p S p(\mathbf{x})|_{2} $$ 其中\(p S p(\mathbf{x})|_{2} = G(E(\mathbf{x}))\)就是最后网络的输出(encoder+styleGAN之后的结果)。为了保证感知相似度,使用了LPIPS损失: $$ \mathcal{L}_{\text {LPIPS }}(\mathbf{x})=|F(\mathbf{x})-F(p S p(\mathbf{x}))|_{2} $$ 式子里面的\(F\)表示感知特征提取器。
3.1.1 The Identity Loss
文章为了保证输入输出是尽可能是一个人,这可不就是最基础的保证了嘛。所以引入一个人脸识别相关的损失: $$ \left.\mathcal{L}_{\mathrm{ID}}(\mathbf{x})=1-\langle R(\mathbf{x}), R(p S p(\mathbf{x})))\right\rangle $$ 这里采用了ArcFace作为人脸编码网络,输入会被crop和resize到112x112输入。
最后整合来看,所有的损失函数叠加起来如下: $$ \mathcal{L}(\mathbf{x})=\lambda_{1} \mathcal{L}{2}(\mathbf{x})+\lambda{2} \mathcal{L}{\mathrm{LPIPS}}(\mathbf{x})+\lambda{3} \mathcal{L}_{\mathrm{ID}}(\mathbf{x}) $$ 各自的权重限制了每一个loss分量的大小。
3.2 The Benifits of the StyleGAN Domain
通过把style来实现image2image的翻译变换使得pSp与常规的方案不一样,因为pSp从全局而非局部去实现翻译,而非pixel2pixel的这种一对一的形式。这是俺们想要的一种属性,因为在非局部变换的时候,局部的偏差限制了逐像素对应的方法的这种变换方法。
前人的工作就有指出,styleGAN学习到的针对语义物体的分离是通过分层地表征来实现的,这就引入了第二个我们想要的东西:多模态数据生成。实现方式也相对很简单了,通过encoder生成latent code,然后进行特征编码生成style(s),然后把通过style mixing的方式将他与一些随机生成的latent code融合起来,在一部分层送入图片的编码,在剩下的层里面送入随机变量。
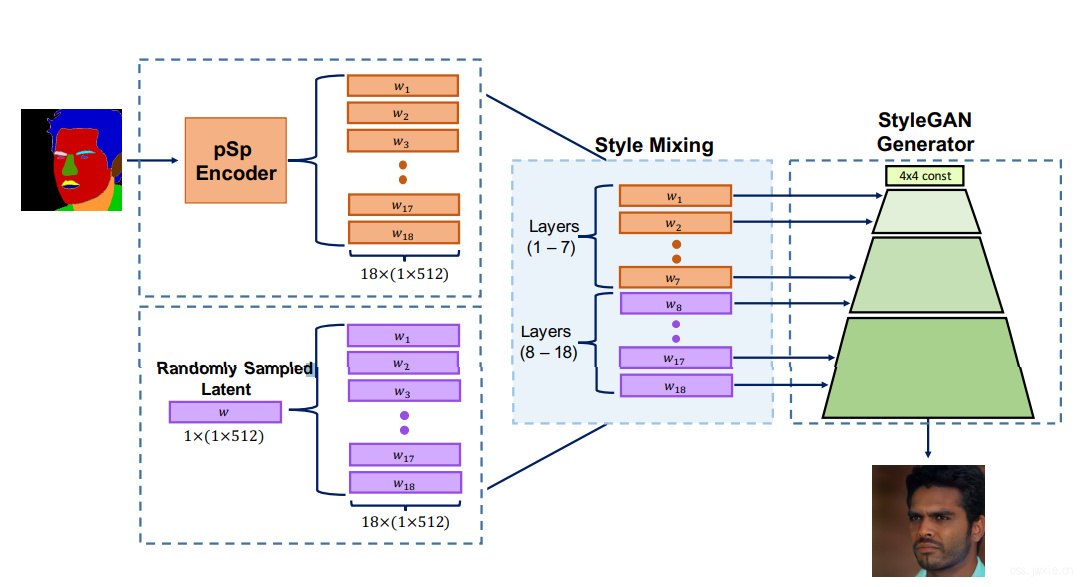 也可以加入\(\alpha\)参数来控制两者的融合,俺们在这里是在coarse和medium层面上使用了encoder输出的styles,剩下的fine层面的特征使用了随机变量,保证我们输出的人是一个人,但是在细节上存在一些变化。
也可以加入\(\alpha\)参数来控制两者的融合,俺们在这里是在coarse和medium层面上使用了encoder输出的styles,剩下的fine层面的特征使用了随机变量,保证我们输出的人是一个人,但是在细节上存在一些变化。
3.3 Implmentation Details
我们使用了ResNet-IR作为backbone(在人脸识别任务中pretrain过了),然后使用固定参数的在FFHQ数据集上训练的styleGAN,输入分辨率位为256x256,输出分辨率为1024x1024。在训练中,使用了Ranger优化器,使用了固定学习率0.001,仅采用了水平镜像作为数据增强策略。除此之外,\(\lambda_{1}=1, \lambda_{2}=0.8, \lambda_{3}=0.1\),训练用的P40。
Section 4 应用与实验
测试了pSp在人脸正面化,条件人脸生成以及超分。
Datasets
CelebA-HQ数据集、FFHQ数据集
Baselines
pix2pixHD作为基准模型
4.1 StyleGAN Inversion
测试了一下与ALAE和IDInvert之间的区别,其中IDInvert只是坐了encoder的前向,没有进行进一步的优化。
Results
结果如下图所示:
 ALAE基本不太行 ,IDInvert能较好的保留图像属性,但没能准确地保留人脸的一致性。
ALAE基本不太行 ,IDInvert能较好的保留图像属性,但没能准确地保留人脸的一致性。
然后坐了一些消融实验。首先用一个encoder生成一个512维向量,然后再encoder最后多加了一层把向量拓展到18个,下图展示了结果。

尽管只是简单的多了一层,坐了一个拓展,但是效果会比直接来好上不少。可是,就算如此,依旧不能保留大多数的细节特征。
 上图展示了如果不加入Identity损失,前后生成的人脸有时候会不是人。
上图展示了如果不加入Identity损失,前后生成的人脸有时候会不是人。
最后,下表给出了一些定量化的评估结果,评估使用了SOTA的Curricularface。
| Method | ↑ Similarity | ↓ LPIPS | ↓ MSE | ↓ Runtime |
|---|---|---|---|---|
| ALAE[37] | 0.06 | 0.32 | 0.15 | 0.207 |
| IDInvert[49] | 0.18 | 0.22 | 0.06 | 0.032 |
| W Encoder | 0.09 | 0.31 | 0.11 | 0.063 |
| Naive W+ | 0.48 | 0.23 | 0.06 | 0.063 |
| pSp | 0.58 | 0.19 | 0.04 | 0.106 |
4.2 Face Frontalization
由于需要进行非局部变换和缺少成对数据的问题,人脸正面化难度还是hin大滴。RotateAndRender通过3D几何对齐来解决这种问题。俺们是直接生成,甚至不需要成对数据的训练。
Methodology and details
主要是两个额外的操作,一是针对target随机flip,造成一些随机的姿态变化,这么搞可以尽可能保证正面化前后的人脸的一致性;二是由于我们并不是太关注背景部分的信息,因此从loss部分做出了一些权重的调整(主要是L2和LPIPS),针对整张图片的中间位置,设置\(\lambda_{1}=0.01, \lambda_{2}=0.8\),针对背景设置\(\lambda_{1}=0.001, \lambda_{2}=0.08\)。
Results
结果如下图所示,基本可以明确的是pix2pixHD没法收敛到一个比较优秀的结果,因为pix2pixHD很大程度上依赖条件因素中的成对信息。pSp的效果还是很不错的,基本与RotateAndRender相当。

4.3 Conditional Image Synthesis
干了两个实验,从素描图和instance map生成高清图像,只需要做一些些小的改变。由于这个任务是一个one2many的任务,因此采用了3.2章节部分的修改来实现了这个功能。
Methodology and details
只采用了L2和LPIPS损失做损失函数,one2many的方案见3.2节的描述。
4.3.1 Face From Sketch
常规的方法是加入硬性约束来保证pixel-wise的对应,确保输入与输出是严格对齐的。这就导致问题变成了病态的了,当输入图像是不完整的,结果就会很离谱。DeepFaceDrawing使用一组分离的网络来解决这个问题,pSp则是提供了一个更简单的方案。
Dataset Construction
有许多数据集可以用比如CUHK,但是这类数据集的素描图像细节都很丰富。因此之类采用了一个和DeepFaceDrawing类似的方案来构建数据集,先用“铅笔画”滤波来去除噪声保留人脸细节,然后采用素描简化方法来生成惟妙惟肖的素描图。然后采用了一样的数据集CelebA-HQ来进行生成素描。
Results
下图对比来了一些与pix2pixHD和DeepFaceDrawing的结果。由于后者没有公开代码,因此对比了一些论文里面你的结果。可以看到,由于pix2pixHD的硬性条件限制,pix2pixHD方法很难去对太过抽象的素描图进行生成。DeepFaceDrawing虽然会好一点,但是依旧效果不是太理想。DeepFaceDrawing的另一个缺陷在于仅侧重了正面的人脸,针对侧脸的数据,对比结果如上图的右边所示。

4.3.2 Face from Segmentation Map
这个过程和上面那个素描转换的任务其实区别其实不是太大。对比实验另外涉及了两个SOTA方案SPADE和CC_FPSE,这俩其实都是基于pix2pixHD的方法。
Results
数据集使用了CelebAMask-HQ,包含了19个语义类别。三种对比模型都是基于pix2pixHD的,所以总的来看结果都大差不差。但是pSp则不一样,pSp可以生成大量有各种姿态和表情的高清图像。然后测了一下其他数据集,图再原文最后面,有兴趣可以去看看,这里不放出来了。
 然后还测了一下多输出的形式,如下图所示。
然后还测了一下多输出的形式,如下图所示。

4.4 Super Resolution
PULSE给出了一个从LR到HR的生成式的超分方案,即将HR图像的manifold下采样到LR的大小,然后通过计算损失来优化输入的无监督方式。pSp也再这方面做出了一些尝试,可以获得和PULSE相比不错的结果。
Methodology and details
pSp使用了全监督的方式来进行训练,针对输入随机进行采样x1,x2,x4,x8和x16然后插值放大到原始大小。
Results
下图给出了结果,pix2pixHD给出了不错的结果,但是less photo-realistic;PULSE能生成高精度图像,但是不是那么的想原来的那个人了。
 然后,针对medium的层设置\(\alpha=0.5\)做style mixing,控制面部特征,pSp也可以生成多个结果,如下图所示。
然后,针对medium的层设置\(\alpha=0.5\)做style mixing,控制面部特征,pSp也可以生成多个结果,如下图所示。

4.5 Additional Applications
展示了三个额外的应用,如下图所示。

局部编辑就是再素描图上做一些修改;人脸插值就是在生成的人脸编码上修改一下,然后再生成图像;人脸修补就是遮住一部分再输入encoder去生成编码。
Section 5 讨论
- 对于styleGAN不能生成的人脸咋办?
- pSp是从全局来考虑的,没有考虑到细节部分,如下图的失败案例。

Section 6 总结
Reference
[1] J. Zhu, Y. Shen, D. Zhao, and B. Zhou. In-domain gan inversion for real image editing. arXiv preprint arXiv:2004.00049, 2020. 2, 3, 5, 6
[2] Baylies. stylegan-encoder. https://github.com/pbaylies/stylegan-encoder, 2019. Accessed: April 2020.
[3] Y. Nitzan, A. Bermano, Y. Li, and D. Cohen-Or. Disentangling in latent space by harnessing a pretrained generator.arXiv preprint arXiv:2005.07728, 2020. 2