SRFlow: Learning the Super-Resolution Space with Normalizing Flow
2020.11.5代码发布啦!!!
Section 0 前置介绍(俺写的,不是论文作者写的)
一些前置的有关于Flow的知识点:
讲到Flow、Glow实际上还得从VAE和GAN说起。针对VAE和GAN我们也比较熟悉了,属于生成模型本质上就是给定一批数据,我们用这批数据来拟合出尽可能真实的数据分布。
这里我们直接从连续变量的角度来讨论。
针对连续变量的分布,实际上是可以用一堆高斯分布来进行拟合的,那么好这里我们定义每一个独立的高斯分布为\(q_{\theta}(\boldsymbol{x}\mid z)\),那针对这个连续变量\(q(\boldsymbol{x})\)的定义实际上就可以用积分来表示:
$$q(\boldsymbol{x}) =\int q(z) q_{\theta}(\boldsymbol{x} \mid z) dz$$
现在要去估计这个连续变量,那么借助最大似然可得:
$$\mathbb{E}_{\boldsymbol{x} \sim \tilde{p}(\boldsymbol{x})}[\log q(\boldsymbol{x})]$$
但是对于这个多个独立高斯分布的积分,有个难题就出来,这咋算?能不能算的出? 这时候蹦出来的两个方案就是VAE和GAN:
- VAE。首先来看VAE,本质上VAE并没有解决这个问题,而是绕过了这个问题,去求解一个一个近似的问题。既然这里要求\(q(\boldsymbol{x})\)涉及到的积分我们并不知道怎么求(举个栗子:这里我们要生成一个小孩的人脸,那就按顺序有五官,头发,脸型等很多问题,那我怎么确定这些问题来让生成的脸是小孩的脸?又或者说这些问题是否能全部被我们考虑到?),或者说这个积分范围具有该有多大也是不清楚的。那么VAE实际上就提出一个绕过这个问题的办法,既然\(q(\boldsymbol{x})\)有点难搞,能不能搞一下\(p(\boldsymbol{x})\)呢,这里我们让\(p(\boldsymbol{x})\)是一个相对简单的分布(还是那个小孩脸的问题,我们简化刚才问题为只需要知道五官,头发和脸型,我们怎么生成小孩的脸),这就是VAE中的V的来源。再从实际的角度上简单地来看这个独立的条件分布的问题,原本的求\(q(\boldsymbol{x})\)的问题实际上就是我们想输入一个latent code直接生成一个东西,那靠小脑袋瓜想想也知道光靠梯度下降要实现这个功能肯定8行嘛。那好,我前面来个编码器,我先输入一个东西让编码器生成latent code然后再用一个解码器实现从latent code到这个东西的过程。这样一看,嗷嗷,这很🆗。总结来看,实际上VAE并没有解决问题,就是绕了一圈去对这个问题的结果近似了一下(这就是为什么VAE通常产生的结果不是太理想的原因)。
- GAN。接着来看GAN,GAN的话其实大家看的也都多了,不详细讲了。GAN本质上就是通过交替训练的方式来绕过这个问题的,相当于多弄了一个额外的监督信息来保证我生成的过程是可靠的,结果也是我们想要的(这里你想想StyleGAN要是没有判别器,那肯定8🉑)。
VAE和GAN都是绕了一下去解决这个问题的,那就没有直面问题的困难的方案么。有,就是Flow,我们可以把积分直接算出来。
假定\(q_{\theta}(\boldsymbol{x} \mid z)\)是个Dirac分布\(\delta(\mathrm{x}-\mathrm{g}(\mathrm{z}))\),然后让\(x=g(z)\)并保证这个\(g\)是个可逆的也就是说: $$x=g(z) \Leftrightarrow z=f(x)$$ 归纳一下,我们原本的算\(q(\boldsymbol{x}) =\int q(z) q_{\theta}(\boldsymbol{x} \mid z) dz\)的计算问题就可以这么理解了: $$q(z)=\frac{1}{(2 \pi)^{D / 2}} \exp \left(-\frac{1}{2}|z|^{2}\right)$$ 然后把\(z\)嵌进去,: $$q(\boldsymbol{x})=\frac{1}{(2 \pi)^{D / 2}} \exp \left(-\frac{1}{2}|\boldsymbol{f}(\boldsymbol{x})|^{2}\right)\left|\operatorname{det}\left[\frac{\partial \boldsymbol{f}}{\partial \boldsymbol{x}}\right]\right|$$ 然后再求一下对数似然: $$\log q(\boldsymbol{x})=-\frac{D}{2} \log (2 \pi)-\frac{1}{2}|\boldsymbol{f}(\boldsymbol{x})|^{2}+\log \left|\operatorname{det}\left[\frac{\partial \boldsymbol{f}}{\partial \boldsymbol{x}}\right]\right|$$ 这个时候,我们想既然\(f\)可以实现从\(x\)到\(z\)的过程,这时候\(f\)又是一个可逆的,这不就🆗了嘛,\( f’=>g \) 就是我们想要的模型。
总结一下,VAE是显式的GAN是隐式的,VAE虽然效果差,但是可以对潜变量做一些编辑,而GAN就不行,因为我们不知道做哪些编辑之后会取得什么样的结果。
Section 1 介绍
SISR是一个比较有趣的研究课题,也有不少重要的实际运用场景。主要的目的就是为了增强给定的图片中丢失的高频信息。但是本质上SR是一个病态的问题,给定一个LR实际上符合的HR图像有不少,这就造成了使用基于深度学习的方法在进行图像的恢复过程中会遇到一堆难题。
早期的方法是使用前馈网络的结构结合\(L_1\)或是\(L_2\)的重建损失函数来进行超分。尽管能取得较好的PSNR指标,但是取得效果肉眼上看就很模糊。然后就有一些工作使用对抗训练和感知损失来解决这个问题,但仍然无法完全解决SR这个病态的问题。
SRFlow解决这个问题的方法是去学习一个在给定LR的条件下,对应的HR所符合的一个合理的条件分布。为此,我们设计了一个条件归一化流(conditional normalizing flow)结构来实现图像的超分辨率。得益于利用对数似然方式对flow进行训练,使网络能够在没有任何其他约束或损失的前提下,学习到如何生成与输入LR图像一致的逼真的SR图像的能力。给定一个LR图像,SRFlow可以从学习到的分布中采样多个不同的SR图像,与传统方法相比,该网络因此可以探索SR图像的整个可能性空间,如下图。

与经典的基于GAN的方法对比的话,这里提出的基于flow的方法有辣么几个优点。首先,SRFlow不存在mode collapse;其次GAN一般需要多个loss来保证训练效果,但这样做的话就有可能对调参和收敛造成一定的困难,而SRFlow的方法就一个损失函数(负对数似然),稳定得多;最有由于基于flow的方法使用了一个可逆的网络,因此可以实现精确的人脸编辑~
贡献:
- 据作者说是第一个设计使用条件归一化流来取得SOTA的超分质量的。
- SRFlow还可以用来做去噪和图像编辑。
- 我们是超分SOTA。
Section 2 相关工作
SISR
SR长久以来就是一个计算机视觉领域里具有一定挑战性的工作,早期的方法基本都是基于稀疏编码或者局部线性回归的方式。第一个使用深度卷积神经网络的是SRCNN,但是这种方式之前也说了不太行。然后就是URDGN和SRGAN以及一些使用cGAN的方法。但这些方法都只能产生一个SR结果。
Stochastic SR
基于生成多张多样的超分解过的方法并没有获得很多的关注。GAN是存在mode collapse的问题的因为GAN再训练过程中很容易就忽略了输入的随机信号,这就导致了很多情况下的超分/图像翻译只能生成定向的结果。[1,2,3]提出了一些基于GAN的随机超分方案,在保证与LR图像尽可能一致的同时实现了能够生成多张图像超分辨率。与其他方案不一样的是,我们设计了一种使用负对数似然进行训练基于flow的结构,这使得我们能够学习到HR图像的条件分布(条件是LR吧?)而不需要更多额外的限制、损失函数、后处理方法来保证SR与LR的相似性。另外还有一些工作[4,5,6],使用数据内部的patch recurrence来训练网络(例如zero-shot/few-shot的一些工作)。但是,我们的想法是弄出一个在一定大的数据集上弄出生成SR图像的一个分布。
其实近期就有关于使用生成流的方式来做超分的,比如PULSE,还有StyleGAN2里面的projcetion,操作起来的基本思路其实很像,后者就是把Normalizing flow换成GAN来做图像生成而已😄,但是我在玩的时候,的确发现了这方面的超分实际上很依赖于backbone模型的生成多样性,也就是SRFlow里面的Glow和PULSE里面用到的StyleGAN<否则PULSE就不会被人骂Racial Discrimination了😂>
Normalizing flow
基于Normalizing flow的方法很少被人关注,Normalizing flow使用一个可逆神经网络\(f_{\theta}\)来参数化一个复杂的分布\(p_{y}(y \mid \theta)\)。这个可逆神经网络可以通过对一个常见的简单分布(比如高斯分布)的采样\(p_{\mathbf{z}}(\mathbf{z})\)映射到\(\mathbf{y}=f_{\theta}^{-\mathbf{1}}(\mathbf{z})\),然后我们就可以使用负对数似然来进行优化。近期也有一个相似的工作[7],但是他们仅坐了2x放大而且没有对比一些基于GAN的最优方法。
Section 3 方法:SRFlow
我们将SR的任务看作是学习一个基于LR图像的,生成HR图像条件分布的任务。该方法旨在通过捕获自然图像Flow中可能存在的各种各样不同的SR图像,来解决超分任务这个病态的问题。为此,我们设计了条件归一化流架构。
3.1 Conditional Normalizing Flows for Super-Resolution
超分任务本质上就是一个通过添加高频特征来对低分辨率的\(\mathbf{x}\)的分辨率进行放大预测,生成一个更高分辨率的\(\mathbf{y}\)的过程。大多数的方法都是通过生成映射的方法\(\mathbf{x} \mapsto \mathbf{y}\),而我们则想通过捕获一个完全条件分布(full conditional distribution)\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\)。相比直接生成一张SR图像,我们这个工作相对更复杂,因为在给定LR的时候我们的条件分布需要覆盖绝大多数的HR图像。我们的目标旨在通过一种纯数据驱动的方式(一堆的LR-HR训练数据对 \(\left(\mathbf{x}{i}, \mathbf{y}{i}\right)_{i=1}^{M}\))对参数\(\theta\)进行训练。
\(f_{\theta}\)实际上就是把HR-LR图像对映射为一个潜变量\(\mathbf{z}=f_{\boldsymbol{\theta}}(\mathbf{y} ; \mathbf{x})\),当然我们要求这个函数必须是可逆的。也就是说,通过潜变量\(\mathbf{z}\)总是可以通过\(\mathbf{y}=f_{\boldsymbol{\theta}}^{-1}(\mathbf{z} ; \mathbf{x})\)重建恢复为HR图像\(\mathbf{y}\)。现在我们假设\(\mathbf{z}\)中的一个简单的分布(比如高斯分布)\(p_{\mathbf{z}}(\mathbf{z})\),且对应的条件分布根据前文已经定义为了\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\),那么这个条件分布就可以由样本\(\mathbf{z} \sim p_{\mathbf{z}}\)的映射\(\mathbf{y}=f_{\boldsymbol{\theta}}^{-1}(\mathbf{z} ; \mathbf{x})\)隐式地被定义。
归一化流的关键在于概率密度\(p_{\mathbf{y} \mid \mathbf{x}}\)是可以有下式明确地计算的: $$p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})=p_{\mathbf{z}}\left(f_{\boldsymbol{\theta}}(\mathbf{y} ; \mathbf{x})\right)\left|\operatorname{det} \frac{\partial f_{\boldsymbol{\theta}}}{\partial \mathbf{y}}(\mathbf{y} ; \mathbf{x})\right|$$ 后面那个部分是雅可比行列式(这个地方就不细讲了,简单来说就是雅可比矩阵可以实现不同空间内的映射,雅可比行列式则是两个映射空间的体积、面积的比例;另一个关键点在于一个函数的雅可比矩阵的逆矩阵就是这个函数的反函数的雅可比矩阵< 😂有点绕哈哈哈哈…. >)。有了这个式子我们就可以用负对数似然来进行优化了: $$\mathcal{L}(\boldsymbol{\theta} ; \mathbf{x}, \mathbf{y})=-\log p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})=-\log p_{\mathbf{z}}\left(f_{\boldsymbol{\theta}}(\mathbf{y} ; \mathbf{x})\right)-\log \left|\operatorname{det} \frac{\partial f_{\boldsymbol{\theta}}}{\partial \mathbf{y}}(\mathbf{y} ; \mathbf{x})\right|$$ 通过把随机生成的潜变量\(\mathbf{z} \sim p_{\mathbf{z}}\)输入到逆网络\(\mathbf{y}=f_{\boldsymbol{\theta}}^{-1}\left(\mathbf{z}{i} \mathbf{x}\right)\)中去就可以从学习到的分布\(p{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\)恢复生成出HR图像\(\mathbf{y}\)。
为了将雅可比行列式换一种更易于表达的表现形式,我们可以将\(f_{\theta}\)分解为一串的N个可逆的层\(\mathbf{h}^{n+1} = f_{\theta}^{n}\left(\mathbf{h}^{n} ; g_{\boldsymbol{\theta}}(\mathbf{x})\right)\),这个串儿的头是\(\mathbf{h}^0=\mathbf{y}\)尾巴是\(\mathbf{h}^N=\mathbf{z}\)。我们首先搞一个深度卷积网络\(g_{\boldsymbol{\theta}}(\mathbf{x})\),然后把输入的LR图像送进去进行编码,提取丰富的特征表达。应用链式法则以及行列式的一些性质,最终NLL的优化函数就变成了如下式:
$$\mathcal{L}(\boldsymbol{\theta} ; \mathbf{x}, \mathbf{y})=-\log p_{\mathbf{z}}(\mathbf{z})-\sum_{n=0}^{N-1} \log \left|\operatorname{det} \frac{\partial f_{\boldsymbol{\theta}}^{n}}{\partial \mathbf{h}^{n}}\left(\mathbf{h}^{n} ; g_{\boldsymbol{\theta}}(\mathbf{x})\right)\right|$$
接下来我们的任务就变成了去对每一个单独的flow层\(f_{\mathbf{\theta}}^{n}\)计算雅可比矩阵\(\frac{\partial f_{\theta}^{n}}{\partial \mathbf{h}^{n}}\)。总体来看,整个结构就如下图所示:
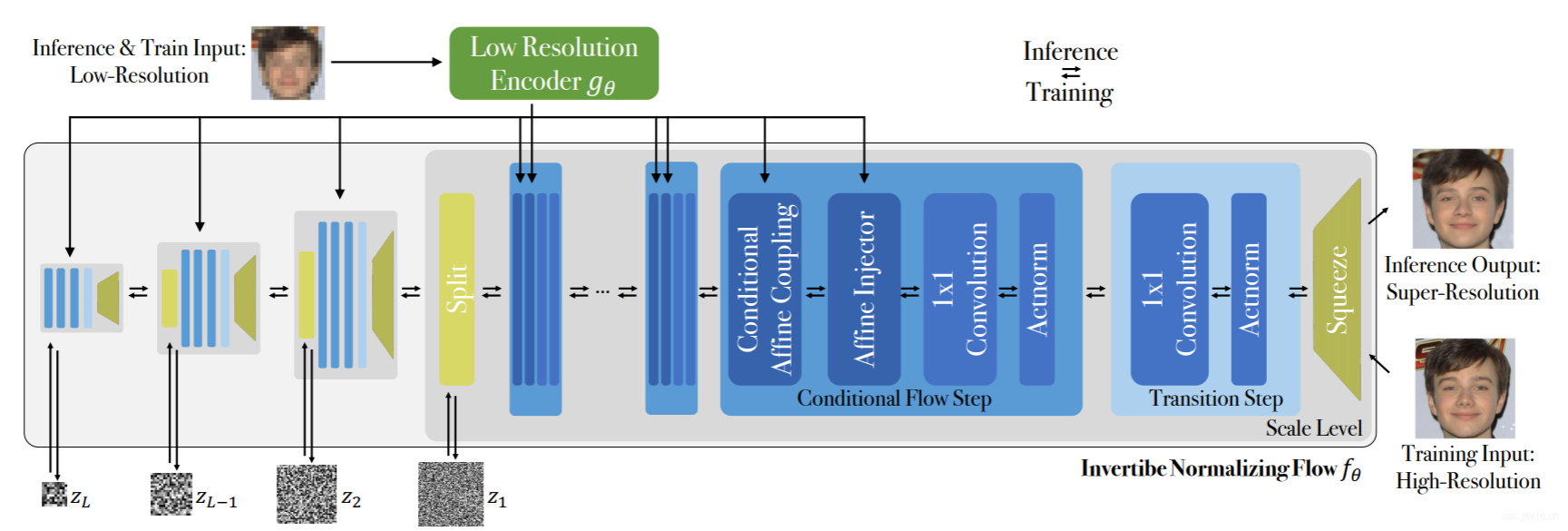
3.2 Conditional Flow Layer
flow层的设计实际上还是很关键的,需要保证能够明确地可逆,并且能够明确地算出雅可比矩阵。本文的工作主要基于无条件的Glow[8]结构(OpenAI那个图像生成的东西),而Glow呢其实也是基于RealNVP。本文这里简单地做一些回顾以便更好地引入Affine Injector层。
Conditional Affine Coupling
仿射耦合(affine coupling)提供了一种简单而有效的构建flow层的策略,并且该策略是可逆的。它可以被简单的拓展为附带条件的形式: $$\mathbf{h}_{A}^{n+1} = \mathbf{h}_{A}^{n}, \quad \mathbf{h}_{B}^{n+1}=e^{f_{\boldsymbol{\theta}, \mathbf{s}}^{n}\left(\mathbf{h}_{A}^{n} ; \mathbf{u}\right)} \cdot \mathbf{h}_{B}^{n}+f_{\boldsymbol{\theta}, \mathbf{b}}^{n}\left(\mathbf{h}_{A}^{n} ; \mathbf{u}\right)$$
在上式中\(\mathbf{h}^{n}=\left(\mathbf{h}_{A}^{n}, \mathbf{h}_{B}^{n}\right)\)是一部分在通道维度上的特征图。此外,\(\mathbf{u}\)是一个条件变量,我们可以将它设置为编码后的输入LR,也就是\(\mathbf{u}=g_{\theta}\left(\mathbf{x}\right)\)。此外要注意的是\(f_{\mathbf{\theta},s}^{n}\)和\(f_{\mathbf{\theta},b}^{n}\)代表产生\(\mathbf{h}_{B}^{n}\)的scaling和bias的任意一个神经网络。
这里加一段自言自语帮助理解下(可能不太正确,欢迎指正) 其实上面那个段间公式很模糊,其实本质上和[0.1]中的分层耦合章节给定的公式7是一致的 $$ \mathbf{h}_1 = \mathbf{x}_1,\mathbf{h}_2 = \mathbf{x}_2 + \mathbf{m}\left(\mathbf{x}_1\right) $$ 只不过这里的第二行的式子从加性耦合改成了加性耦合与乘性耦合的结合=>仿射耦合 $$\begin{array}{l} \boldsymbol{h}_{1}=\boldsymbol{x}_{1}, \boldsymbol{h}_{2}=\boldsymbol{s}\left(\boldsymbol{x}_{1}\right) \otimes \boldsymbol{x}_{2}+\boldsymbol{t}\left(\boldsymbol{x}_{1}\right) \end{array}$$ 这俩货分别在NICE和RealNVP中有一定的介绍。 那么这么来看,我们可以很明确的得出雅可比矩阵: $$\left[\frac{\partial \boldsymbol{h}}{\partial \boldsymbol{x}}\right]=\left(\begin{array}{cc} \mathbb{I}_{d} & \mathbb{O} \\ {\left[\frac{\partial \boldsymbol{s}}{\partial \boldsymbol{x}_{1}} \otimes \boldsymbol{x}_{2}+\frac{\partial t}{\partial \boldsymbol{x}_{1}}\right]} & \boldsymbol{s} \end{array}\right)$$ 可以看出这个雅可比矩阵的行列式是一个明确的三角阵,行列式的值巨好求,结果就等于\(\mathbf{s}\)的个元素乘积(既然行列式的值在空间上又代表了体积,所以代表着体积是由变化的–对应加性变换中体积恒为1)。 但是前面我们提到雅可比矩阵要求是可逆的,那么就可以做一些宽泛的约束比如令\(\mathbf{s}\)的各个元素的值都大于0。
回到文中式子,为了简化计算,使用自然对数将乘积转换为求和。
Invertible 1 × 1 Convolution
一般的卷积通常无法反转,但是有文献展示了使用1 × 1的卷积\(\mathbf{h}_{i j}^{n+1}=W \mathbf{h}_{i j}^{n}\),既然我们要进行置换矩阵的通道(那就自然引入了一个置换矩阵),也就自然而言的想到,那这里为什么不使用一个带参数的卷积来替代呢(这里由一个计算上的trick,利用三角分解来简化计算具体可看[0.3])。
Actnorm
通过一个学到的的scaling和bias,提供了一个channel-wise的标准化方法。
Squeeze
在跨越网络的各个深度层次,通过对不同尺度的激活层的处理来捕获相关信息和结构信息是很重要。Squeeze通过将2x2的一个四元素的小邻域拆分成四个激活层来实现可逆下采样(这就很像是超分的sub-pixel)。
Affine Injector
为了实现从低分辨率的图像编码\(\mathbf{u}=g_\mathbf{\theta}\left(\mathbf{x}\right)\)到flow分支上能有更直接的特征信息传递,本文引入了一个额外的Affine Injector(仿射变换注入层)。与传统的比,加入了Affine Injector能仅通过调整编码\(\mathbf{u}\),就可以直接影响到通道和空间位置的变换。(这里讲到文章的整体结构,可以看一下上面整个的流程图,一共有\(l \in\{1, \ldots, L\}\)层,每一层有\(K\)个flow-steps,\(f_\theta\)和\(g_\theta\)分别代表了可逆的flow网络和LR编码网络)
3.3 Architecture
上面那张图已经详细描绘了SRFlow的结构,具体的包含了flow网络\(f_{\theta}\)和LR的编码网络\(g_{\theta}\)。对于前者,总体被划分为L个levels,每一个level里包含有K的flow-steps。
Flow-step
我们的网络结构中每一个flow-step都包含四个不同的层。如果第一层是Actnorm那么后面会紧跟一个1 x 1的卷积,然后再放两个条件层。如果第一层是Affine Injector,那么后面紧跟的就是条件Affine Coupling。
Level transitions
每一层都首先弄一个squeeze操作减半分辨率,但是我们注意到这个操作会导致重建的图像会存在棋盘伪影,因为squeeze本质上就是基于一个pixel重排。为了能更好的让特征信息再层间传递,我们尝试再钱买你几个flow-steps中挪掉了squeeze后的条件层,这使得网络可以从周围的像素中学到一些可逆线性的插值信息。与[8]相似,我们在下一个squeeze层前,将通道数55开了一下。因此,我们的潜变量\(\left(z_{l}\right)_{l=1}^{L}\)能够更好的对不同分辨率的图像信息进行建模。
Low-resolution encoding network \(g_{\theta}\)
SRFlow的LR编码网络\(g_{\theta}\)可以用任意的结构,因为本身这部分结构是不需要可逆的。因此,我们的方法可以获益于常用的前馈SR网络结构。特别的,我们采用了流行的Residual-in-Residual Dense Blocks(RRDB)模块。它采用了多个残差和密集的skip connection,并且不加入任何的BN层。SRFlow丢掉了最后的上采样层,因为SRFlow需要的只是一个编码器。为了获取更丰富的表征特征,我们额外地将RRDB块后的输出都级联起来了最后形成\(g_{\theta}\)的输出。
Details
我们在每一个level采用K=16个flow-steps,另外添加了两个额外的无条件flow-steps在squeeze层后面(前面讨论过)。对L=3和L=4,设置为4倍放大和8倍放大的输出。对于通用图像的SR,使用了23个blocks的RRDB结构来构建编码器。针对人脸SR为了效率,减少了8个blocks。对于网络\(f^{n}_{\theta,s}\)和\(^{n}_{\theta,b}\),使用了两个共享卷积层和ReLU来进行构建,然后是最后一层的一个卷积层。
3.4 Training Details
我们使用负对数似然损失来训练整个SRFlow网络。batchsize大小是16。在训练过程中,HR图像块的大小为160x160。使用Adam作为优化器,起始学习率为5e10-4,分别在50%,75%,90%和95%的时候减半学习率。为了提高训练效率,首先使用L1损失对编码器\(g^{n}_{\theta,b}\)进行200k次的预训练。然后再进行200k次迭代,训练完整SRFlow架构。网络在单个NVIDIA V100上进行训练需要5天。附录中提供了进一步的细节。
数据集
对于人脸超分辨率,我们使用CelebA数据集。我们通过裁剪Patches来进行数据集预处理,其中HR的Patch分辨率被调整为160×160。我把所有图像都分作训练集(160k张图像)。对于通用图像的超分辨率,我们使用与ESRGAN相同的训练数据,包括800个DIV2k的训练数据以及来自Flickr2K的2650张图像。LR图像使用标准的MATLAB双三次下采样核进行构建。
Section 4 应用与图像处理
在本节中,我们将探讨SRFlow网络的各种应用和图像处理任务中的使用。该技术利用了SRFlow的两个关键优势,这在基于GAN的超分辨率方法中是不存在的。首先,我们的网络在HR图像空间中模拟一个分布\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\),而不是只预测单个图像。因此,SRFlow具有很大的灵活性。这使得我们可以利用额外的监督信息或随机抽样来获得不同的预测结果。
其次,Flow网络\(f_{\boldsymbol{\theta}}(\mathbf{y} ; \mathbf{x})\)是一个完全可逆的编码/解码结构。因此,任何HR图像\(\tilde{\mathbf{z}}\)都可以被编码到潜空间中,作为\(\tilde{\mathbf{z}}=f_{\boldsymbol{\theta}}(\tilde{\mathbf{y}} ; \mathbf{x})\),并精确地重建为\(\tilde{\mathbf{y}}=f^{-1}_{\boldsymbol{\theta}}(\tilde{\mathbf{z}} ; \mathbf{x})\)。这种双向对应关系,使我们可以在潜空间和图像空间中反复横跳。
4.1 Stochastic Super-resolution
SRFlow学习到的分布\(f_{\boldsymbol{\theta}}(\mathbf{y} ; \mathbf{x})\)可以通过对给定的LR图像\(x\)的不同SR预测,进行一些采样和探索\(\tilde{\mathbf{y}}=f^{-1}_{\boldsymbol{\theta}}(\tilde{\mathbf{z}} ; \mathbf{x})\),\(\mathbf{z}^{(i)} \sim p_{\mathbf{z}}\)。通常观察到的基于流的模型,当降低采样的方差时,可以获得最佳的结果。因此,我们使用方差为\(\tau\)的高斯\(\mathbf{z}^{(i)} \sim \mathcal{N}(0, \tau)\)(也称为温度)。\(\tau=0.8\)时,结果在下图中做了一些可视化。

SRFlow生成了大量的SR图像,包括例如头发和面部属性的差异,同时保持了与LR图像的一致性。由于我们的潜变量\(z_{ijkl}\)是与生成图像密切相关,特定的部分可以重新采样,使得SR图像的交互式编辑和探索更加可控。
4.2 LR-Consistent Style Transfer
SRFlow允许在LR图像x时转移现有HR图像\(\tilde{\mathbf{y}}\)的样式。这是通过首先将源HR图像编码为\(\tilde{\mathbf{z}}=f_{\boldsymbol{\theta}}\left(\tilde{\mathbf{y}} ; d_{\downarrow}(\tilde{\mathbf{y}})\right)\),其中\(d_{\downarrow}\)是缩放算子。这个编码\(\tilde{\mathbf{z}}\)就可以后续用作\(x\)的超分辨率的潜变量,为\(f_{\boldsymbol{\theta}}^{-1}(\tilde{\mathbf{z}} ; \mathbf{x})\)。这种操作也可以在图像的局部区域上进行。图4给出了一些例子显示了面部特征、头发和眼睛颜色等风格的变化。SRFlow网络旨在自动确保与LR图像的一致性,而不需要任何额外的约束。
4.3 Latent Space Normlization
利用SRFlow网络\(f_\theta\)可逆的优势,以及借助了学习到的超分辨率的后验,我们弄了一个超屌的图像编辑技术。我们的方法的核心思想是将任何包含有的HR图像映射到目标所在的到潜空间,在这里,潜变量的一些统计可以被归一化,以使其与给定的LR图像所包含的信息一致。让\(\mathbf{x}\)是低分辨率图像,\(\tilde{\mathbf{y}}\)是_任意的_高分辨率图像,且不一定与LR图像\(\mathbf{x}\)一致。例如,\(\tilde{\mathbf{y}}\)可以是一个对超分后的图像进行编辑过的结果,或者是一个超分的知道图像(雾..?)。我们的目标是从\(\tilde{\mathbf{y}}\)获得一个HR图像\(\mathbf{y}\),且与LR图像\(\mathbf{x}\)一致。
给定图像对的潜编码计算为\(\tilde{\mathbf{z}}=f_{\theta}(\tilde{\mathbf{y} ; \mathbf{x}})\)。需要注意的是网络被训练为预测从标准高斯分布\(p_{\mathbf{z}}=\mathcal{N}(0, I)\)中采样的潜变量的一致和自然SR图像。
由于\(\tilde{\mathbf{y}}\)不一定与LR图像\(\mathbf{x}\)一致,所以潜变量\(\tilde{\mathbf{z}}_{ijkl}\)的统计量与独立采样时的统计量不一样\(\mathbf{z}_{ijkl}\sim \mathcal{N}(0, \tau)\)。\(\tau\)表示目标潜分布的附加温度缩放。为了达到期望的统计量,我们对潜变量集合的前两个矩进行归一化。特别的,如果\({z_i}_1^N \sim \mathcal{N}(0, \tau)\)是独立的,那么众所周知它们的经验均值\(\tilde{\mu}\)和方差\(\tilde{\delta}^2\)是根据以下的式子分布的: $$\hat{\mu}=\frac{1}{N} \sum_{i=1}^{N} z_{i} \sim \mathcal{N}\left(0, \frac{\tau}{N}\right), \hat{\sigma}^{2}=\frac{1}{N-1} \sum_{i=1}^{N}\left(z_{i}-\hat{\mu}\right)^{2} \sim \Gamma\left(\frac{N-1}{2}, \frac{2 \tau}{N-1}\right)$$ 其中,\(\Gamma(K, \theta)\)是一个伽马分布。在给定的一个潜变量的集合\(\tilde{\mathcal{Z}} \subset{\mathbf{z}_{i j k l}}\),可以首先通过上式采样一个新的均值\(\tilde{\mu}\)和方差\(\tilde{\delta}^2\),其中\(N=|\tilde{\mathcal{Z}}|\)是这个集合的大小,来对这个统计量进行标准化。集合中的潜变量的归一化如下式所示: $$\hat{z}=\frac{\hat{\sigma}}{\tilde{\sigma}}(\tilde{z}-\tilde{\mu})+\hat{\mu}, \quad \forall \tilde{z} \in \tilde{\mathcal{Z}}$$ 式中,\(\tilde{\mu}\)和\(\tilde{\delta}^2\)表示的是集合\(\mathcal{Z}\)的均值和方差的经验分布。

上式中的归一化可以使用不同的集合\(\mathcal{\tilde{Z}}\)来进行表示。在这项工作中考虑了具体三种不同的策略。全局归一化是在整个潜空间上进行的,通过\(\tilde{\mathcal{Z}}=\left\{\mathbf{z}_{i j k l}\right\}_{i j k l}\)。对于局部归一化,每个层次\(l\)中的每个空间位置\(i,j\)都独立进行归一化,通过\(\tilde{\mathcal{Z}}_{ijl} = \{\mathbf{z}_{ijkl}\}_k\)。这样可以较好地解决统计量在空间上变化的情况。此外还可以对每个特征通道\(k\)和级别\(l\)独立进行空间归一化,通过\(\tilde{\mathcal{Z}}_{kl} = \{\mathbf{z}_{ijkl} \}_{ij}\)。它解决了图像中激活某些通道的全局效应,如色移或噪声。
在所有三种情况下,通过对所有集合应用上面的式子获得归一化潜变量\(\tilde{\mathbf{z}}\),这是一种易于并行化的计算。然后将最终的HR图像重构为\(\tilde{\mathbf{y}} = f_\mathbf{\theta}^{-1}(\tilde{\mathbf{z}}, \mathbf{x})\)。需要注意的是归一化过程是随机的,因为每一个潜变量\(\tilde{\mathcal{Z}}\)的集合都会独立地抽取一个新的均值\(\tilde{\mu}\)和方差\(\tilde{\delta}^2\)。这使得我们可以从自然而多样的预测\(\tilde{\mathbf{y}}\)中采样。接下来,我们探索我们的潜空间归一化技术的不同的应用方向。
4.4 Image Content Transfer
在这一小节,目的是通过转移其他图像内容迁移到当前图像上。\(x\)是一个LR图像,\(y\)是一个与\(x\)相应的HR图像。如果我们迁移的是一个超分辨率结果图像,那么\(y=f_{\theta}^{-1}(\mathbf{z}, \mathbf{x})\)是\(x\)的SR结果。然而,我们知道我们也可以通过将\(\mathbf{x} = d_{\downarrow}\mathbf{y}\)设置为\(y\)的低分辨率版本来操纵现有的HR图像\(y\),然后就可以简单地从其他图像中插入内容来直接在图像空间中操纵\(y\),如图5所示。在生成图像\(\tilde{\mathbf{y}}\)的过程中,为了通过确保与LR图像\(x\)的一致性,我们计算潜编码\(\tilde{\mathbf{z}} = f_{\theta}(\tilde{\mathbf{y}}; \mathbf{x})\),并对潜伏变量做_局部归一化_,如上4.3节所述。我们只对图像的受影响区域进行归一化,以保留修改区域的内容。结果如图5所示。如果需要,可以通过用随机错位的HR-LR对训练SRFlow来减少对LR一致性的强调,这样可以增加内容迁移的灵活性(见附录)。
4.5 Image Restoration
在本节,我们通过将其应用于图像恢复任务来证明SRFlow的所需到的图像后验的能力强度。请注意,我们在这里采用了相同的SRFlow网络(仅针对超分辨率进行训练,而不是针对人脸expore的)。特别是,我们主要研究影响图像中高频的退化的因素,如噪声和压缩伪影。使\(\tilde{\mathbf{y}}\)是一个退化的图像。当进行下采样\(\mathbf{x}=d_{\downarrow}(\tilde{\mathbf{y}})\)获得\(x\)时,噪声和其他高频退化被大量去除。因此,可以通过对\(x\)应用任何超分辨率方法来获得干净的图像。然而,这产生的结果很差,因为除了丢了噪声和退化信息,更为重要的图像信息在下采样过程中也大量丢失了(图6,中间)。
我们的方法可以跨越这个问题,直接利用原始图像\(\tilde{\mathbf{y}}\)。退化图像以及它的下采样版本输入到SRFlow中生成潜变量\(\tilde{\mathbf{z}} = f_{\theta}(\tilde{\mathbf{y}}; \mathbf{x})\)。然后,对\(\tilde{\mathbf{z}}\)进行空间和局部归一化。然后,将还原后的图像输出\(\hat{\mathbf{y}}=f_{\boldsymbol{\theta}}^{-1}(\hat{\mathbf{z}}, \mathbf{x})\)。
如果把归一化操作表示为\(\hat{\mathbf{z}}=\phi(\tilde{\mathbf{z}})\),完整的还原映射可以表示为\(\hat{\mathbf{y}}=f_{\boldsymbol{\theta}}^{-1}\left(\phi\left(f_{\boldsymbol{\theta}}\left(\tilde{\mathbf{y}} ; d_{\downarrow}(\tilde{\mathbf{y}})\right)\right), d_{\downarrow}(\tilde{\mathbf{y}})\right)\)。如图6中直观和定量地显示,这使我们能够从原始图像中恢复大量的细节。直观地讲,该通过将退化的图像\(\tilde{\mathbf{y}}\)映射到学习分布\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\)内最近似的一张图像来实现重建。由于SRFlow不是用这样的数据来进行训练的,\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\)主要是为了生成干净的图像。因此,Flow的归一化会根据SR的分布\(p_{\mathbf{y} \mid \mathbf{x}}(\mathbf{y} \mid \mathbf{x}, \boldsymbol{\theta})\),自动将图像转化为更高清的图像。
Section 5 实验
Section 6 结论
\(\uparrow\)这两节都是细节和秀肌肉的部分,具体的不在这里讲了,有兴趣的可以自己去看一下。以上!
Reference
[0.1] https://www.sohu.com/a/246846378_500659
[0.2] https://zhuanlan.zhihu.com/p/55557709
[0.3] https://kexue.fm/archives/5807
[1] Bahat, Y., Michaeli, T.: Explorable super resolution. In: CVPR (2020)
[2] B¨uhler, M.C., Romero, A., Timofte, R.: Deepsee: Deep disentangled semantic explorative extreme super-resolution. arXiv preprint arXiv:2004.04433 (2020)
[3] Menon, S., Damian, A., Hu, S., Ravi, N., Rudin, C.: Pulse: Self-supervised photo
upsampling via latent space exploration of generative models. In: CVPR (2020)
[4] Bell-Kligler, S., Shocher, A., Irani, M.: Blind superresolution kernel estimation using an internal-gan. In: NeurIPS. pp. 284–293 (2019), http://papers.nips.cc/paper/8321-blind-super-resolution-kernel-estimation-using-an-internal-gan
[5] . Shaham, T.R., Dekel, T., Michaeli, T.: Singan: Learning a generative model from a single natural image. In: ICCV. pp. 4570–4580 (2019)
[6] Shocher, A., Cohen, N., Irani, M.: Zero-shot super-resolution using deep internal learning. In: CVPR (2018)
[7] Winkler, C., Worrall, D.E., Hoogeboom, E., Welling, M.: Learning likelihoods with conditional normalizing flows. arxiv abs/1912.00042 (2019), http://arxiv.org/abs/1912.00042
[8] Kingma, D.P., Dhariwal, P.: Glow: Generative flow with invertible 1x1 convolutions. In: Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montr´eal, Canada. pp. 10236–10245 (2018)