TENSORRT DOCUMENTATION
TENSORRT 中文文档 - 开发者指南
摘要
这个开发人员指南(基于TensorRT 7.2.0)演示了如何使用C++和Python API来实现最常见的深度学习层。这个指南展示了如何使用由现有的深度学习框架以及现有的网络层所搭建的模型来创建一个TensorRT引擎。这份开发人员指南还提供了针对常见用户任务的分步说明,例如创建TensorRT的网络定义,调用TensorRT builder,序列化和反序列化,以及如何向引擎提供数据并执行推理;这份指南同时包含了使用使用C++或Python API的方法。
1. 什么是TensorRT
NVIDIA® TensorRT™的核心是一个C++库,可实现在NVIDIA图形处理单元(GPU)设设备上的高性能推断。它旨在与TensorFlow,Caffe,PyTorch,MXNet等训练框架以互补的方式工作。它专门致力于在GPU上快速有效地运行训练完成的网络,生成结果(这个过程在各个细分领域通常也被称为评分,检测,回归或推断)。
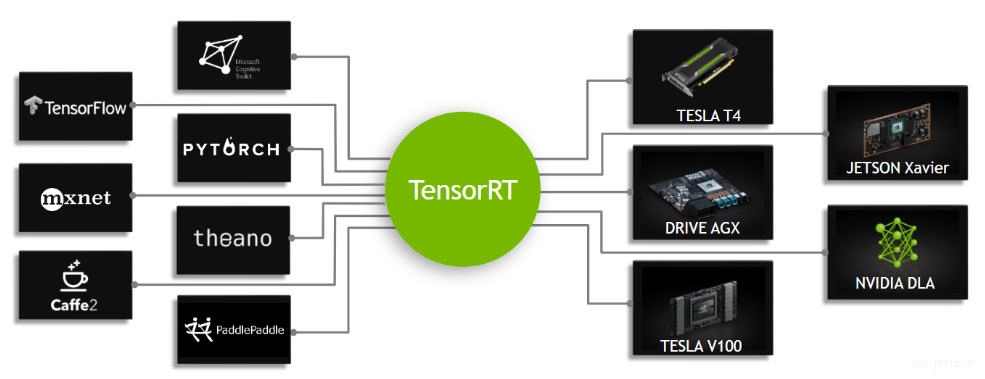
一些训练框架(例如TensorFlow)已经集成了TensorRT,因此可以直接在框架的基础上实现加速推理。另外,TensorRT也可以作为一个用户可调用的应用,以库的形式安装在设备中。它包含了从现有的框架如Caffe,ONNX或TensorFlow导入现有模型的解析器,以及用于通过编程的方式来构建模型的C++和Python API。
图1. TensorRT是用于生产部署的高性能神经网络推理优化器和运行时引擎(Runtime Engine)。
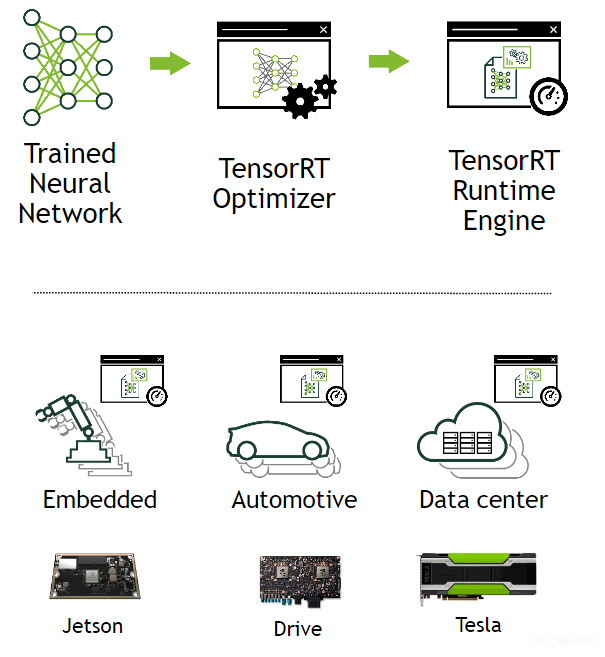
TensorRT通过组合层和优化计算内核选择来优化网络,以降低延迟,提高吞吐量,降低能效和减少内存消耗。如果应用程序指定,它将额外通过使用低精度的计算方式来优化网络的内存需求。
下图显示了使用TensorRT被定义为一个高性能推理优化器和运行时引擎的桥梁。它可以将这些流行的网络框架上训练好的模型作为输入,通过优化神经网络计算,生成一个轻量级的运行时引擎(这是唯一一个需要被你部署到生产环境中的东西),它将大量提升吞吐量,降低延迟以及提升在GPU平台上的推理性能。
图2. TensorRT是一个可编程的推断加速器
TensorRT API涵盖了大多数常见的深度学习层的实现。有关更多有关层的详细信息,请参见TensorRT图层。 您还可以使用C++ API或Python API为TensorRT添加一些目前TensorRT不支持,或者通常来说不那么常用用的或者更具创新性的即开即用的层。
1.1 使用TensorRT的优势
在网络训练完成后,TensorRT可以压缩网络模型,在运行时(Runtime)不断优化和部署,而无需担心模型框架的实现在部署上的计算负担。
TensorRT根据指定的精度(FP32,FP16或INT8)组合各层,优化计算内核的选择,并进行规范化,讲运算转换为优化后的的矩阵数学运算,以改善延迟,吞吐量和效率。
对于深度学习推理,有五个用于衡量软件的关键因素:
吞吐量
给定时间段内的产出量。吞吐量通常以前向推理次数/秒或样本数/秒来衡量,单台服务器的吞吐量对于数据中心经济高效地扩展至关重要。
效率
每单位功率交付的吞吐量,通常表示为性能/瓦特来衡量。效率是经济高效地扩展数据中心的另一个关键因素,因为服务器、服务器机架以及整个数据中心必须在固定的功率预算内运行。
时延 执行推理的时间,通常以毫秒为单位。低延迟对于提供快速增长的基于实时推理的服务至关重要。
准确性 训练完成的神经网络能够提供正确答案。对于基于图像分类的用法,关键指标表示为top-5和top-1准确率。
内存消耗 运行算法所需要预留的主机与设备的显存空间。这限制了哪些网络以及网络的哪些组合可以在给定的推理平台上运行。这对于需要多个网络且内存资源有限的系统尤其重要,例如,在智能视频分析场景下级联多类物体检测网络,或是多摄像头、多网络模型的自动驾驶系统场景。
不使用TensorRT的场景包括:
- 使用训练框架本身执行推断。
- 编写专门设计用于使用低级库和数学运算来执行网络的自定义应用程序。
使用训练框架执行推理很容易,但是与使用TensorRT之类的优化解决方案相比,在给定GPU上的性能往往低得多。 训练框架倾向于强调使用通用性更强的代码,它的优化更侧重于如何有效地训练上。
通过编写仅用于执行神经网络的自定义应用程序可以获得更高的效率,但是,这可能会非常费力,并且需要大量专业知识才能在GPU设备上达到较高的性能水平。 此外,在一个GPU上进行的优化可能无法完全转换为同一系列中的其他GPU,并且每一代GPU都可能引入只能通过编写新代码来利用的新功能。
TensorRT通过结合抽象出特定硬件细节的高级API和优化推理的实现来解决这些问题,以实现高吞吐量,低延迟和较低地设备内存消耗。
1.1.1 使用TensorRT可以使谁获益
TensorRT供负责基于新的或现有的深度学习模型构建功能和应用程序或将模型部署到生产环境中的工程师使用。这些部署可能位于将在您的工作站上运行的数据中心或云中的服务器,嵌入式设备,机器人或车辆或应用程序软件中。 TensorRT已在多种场景中成功使用,包括: 机械人 公司出售使用TensorRT来运行各种计算机视觉模型的机器人,以自动引导在动态环境中飞行的无人机系统。
自动驾驶汽车 TensorRT用于支持NVIDIA Drive产品中的计算机视觉。
科技计算 TensorRT嵌入了一种流行的技术计算包,可实现神经网络模型的高吞吐量执行。
深度学习培训和部署框架 TensorRT包含在几种流行的深度学习框架中,包括TensorFlow和MXNet。有关TensorFlow和MXNet容器发行说明,请参阅TensorFlow发行说明和MXNet发行说明。
视频分析 NVIDIA DeepStream产品中使用TensorRT在边缘(具有1-16个摄像机源)和数据中心(可能聚集数百甚至数千个视频源)中为复杂的视频分析解决方案提供支持。
自动语音识别 TensorRT用于在小型台式/台式设备上支持语音识别。设备上支持有限的词汇表,而云中提供了更大的词汇表语音识别系统。