Learning to Cartoonize Using White-box Cartoon Representations
🔗 PDF Link 🍺 Github Code
本以为是动画化的下一版是AnimeGAN2(虽然前两天看也发布了代码了 0.0),结果是这个… 😄
Section 1 介绍
实际上现实下的动画风格多种多样,针对黑盒模型来说困难重重,对于多种多样的实际需求,单纯地更换数据集本质上并不能取得很好地效果。例如CartoonGAN提出了edge loss,但是在实际训练过程中,这带来了强烈地风格化并降低了通用性,这就使得运用场景被局限于一些特定的场景。
作者调研了好多风格的动画和立绘(好家伙,上班时间看动画😄),提出了将图像decompose到一些列的动画表征中去:
- surface representation,用来表现图像中平滑的surface。众所周知啦,图像的低频信息占了大多数,包括了颜色成分和图像表面纹理,构成了整个图像画面的surface部分(换句话说没有+任何一点点的细节)。
- structre representation,用来获取全局的结构信息,并解析动画样式的颜色风格。实际上就是获取了segmentation map然后,采用一些自适应上色的算法来解决颜色问题。
- texture representation,用来保留细节部分东西。具体地就是把输入图像转换成单通道的强度图,去掉了颜色信息和亮度信息,只保留了图像的相对强度(这里就是高频信息部分的转换了)。
以这种序列化的方式来提取特征的方式能够让GAN来优化这个动画化的问题。总体的贡献如下所示:
- 提出了三种动画表征,这三个表征实际上也是根据从业者的实际作画场景来进行设计的,因此有相对较强的合理性。
- 使用了基于GAN的优化框架,在具体的优化过程中,依赖提取到的三种不同的表征来进行优化。因此,调整三者的权重可以平衡最终生成的效果。
- 常规操作,提一下自己是SOTA。
Section 2 相关工作
这部分简单介绍,具体的自己调研~
2.1 Image Smoothing and Surface Extraction
图像平滑实际上是一个研究领域,早期的方法基本上都是基于滤波的方法,近些年来基于学习的方法开始渐渐流行。本文这里使用的是可微分的导向性滤波器来进行提取。
2.2 SuperPixel and Structure Extraction
一些流行的超像素分割算法是将像素节点作为node,将nodes之间的相似度作为edge,以图的形式来构建。基于梯度下降的方法则是通过迭代优化来梯度来将clusters分组。本文这里使用的felzenszwalb[1]的方法。
2.3 Non-photorealistic Rendering(NPR)
NPR在转换图像分割一直很重要。Neural Style Transfer方法是一种相对流行的方法,通过将一张图像的内容与另一张图像的风格融合来进行图像生成。除此之外,NPR还被广泛的应用于图像的抽象,剥离图像中的细节,保留抽象视觉信息。本文使用的方法则是从一组动画图像中抽取动画图像的分布,而不是单张图像的转换。
2.4 Generative Adversarial Networks
2.5 Image-to-image Translation
Section 3 方法
整体来看就是把图像分解成三个部分,然后使用三个独立模块来提取特征特征。采用了一个生成器和两个判别器\(G_s\)和\(G_t\)的GAN模型,前者用于计算生成图像和动画图像在surface representation层面上的差异,后者用于评估texture representation层面上的差异。还增加了一个预训练的VGG用于限制全局内容的差异性。整体流程如下图所示:
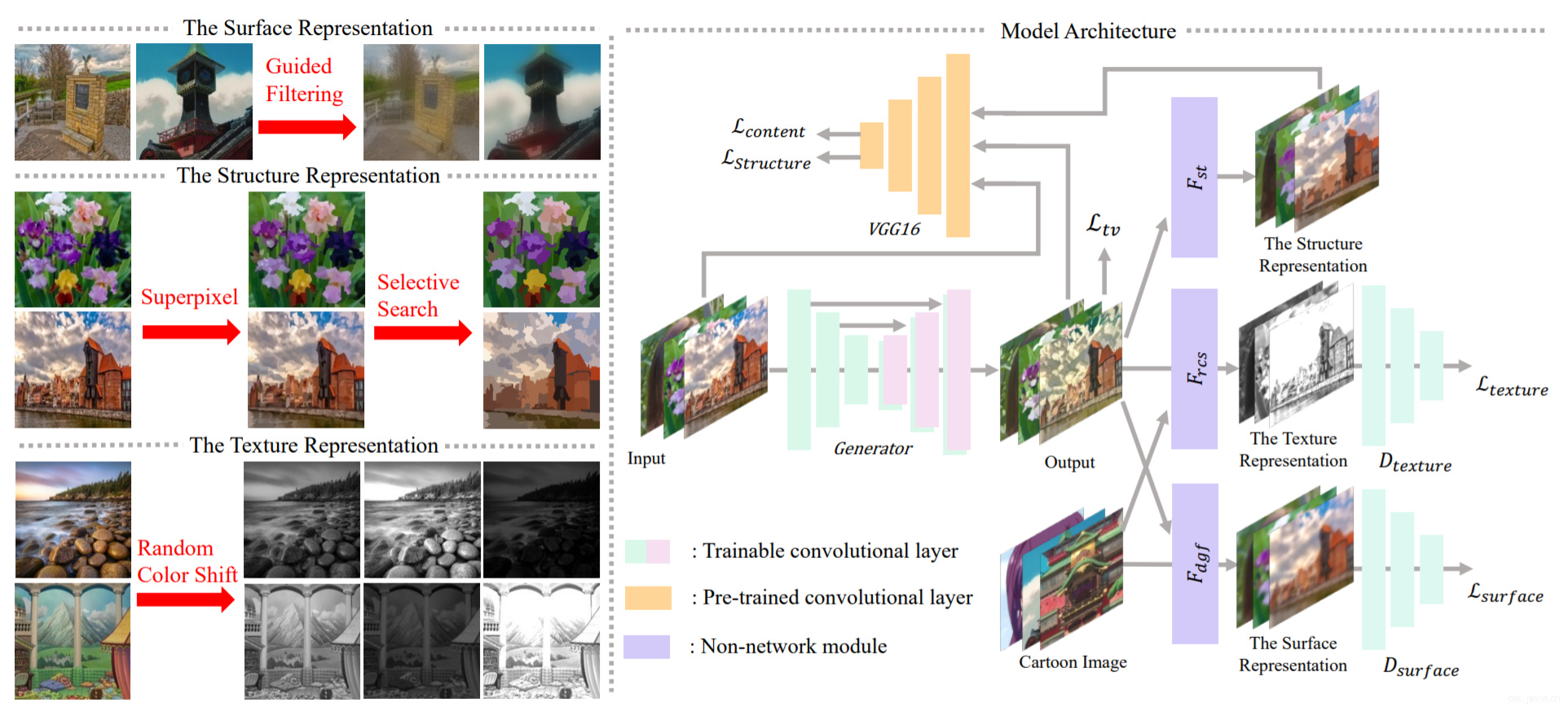
3.1 Learning From the Surface Representation
Surface Representation是通过模仿人类画师在构建动画图像样式的图像中的方法,用粗画笔画出大致的草稿以及平滑的大致构图。为了平滑图像并保留全局的语义信息,构建了一个可微分的监督滤波器\(\mathcal{F}_{dgf}\),输入和监督图都是图像本身,最终会返回一个去掉细节和纹理的输出(有点小奇怪,为什么监督信息是输入本身,输出却是这样的?)。
设计了一个特定的判别器来判断模型的输出是否与动画图像的surface representation有较高的相似度,这里我们让\(I_{p}\)和\(I_{c}\)分别代表输出的动画图像和真实的动画图像,因此可以设计一个损失函数如下:
$$\begin{aligned} \mathcal{L}_ {\text {surface}}\left(G, D_{s}\right)=\log D_{s}(\mathcal{F} {\text {dgf}} (\boldsymbol{I}{c}, \boldsymbol{I}{c})) +\log \left(1-D{s}\left(\mathcal{F}_ {\text {dgf}}\left(G\left(\boldsymbol{I}_ {p}\right), G\left(\boldsymbol{I}_{p}\right)\right)\right)\right) \end{aligned}$$
3.2 Learning From the Structure Representation
结构表征是去模仿动画图像中平整的全局内容、颜色块以及清晰的边界等内容。首先用超像素分割的方法然后结合Selective Searching来整合相似的超像素区域,从而获取一个稀疏分割图。
标准的超像素方法是使用平均颜色来给超像素区域上色,但是在我们研究了后续的数据集后,我们发现这么做会显著地降低图像地全局对比度,最终会导致生成的图像暗+浑浊,如下图所示。

为此,文章提出了一种自适应上色算法,如下式:
$$ \boldsymbol{S}_{i,j} = ( \theta _{1} * \overline{\boldsymbol{S}}+\theta _{2} * \tilde{\boldsymbol{S}})^{\mu}$$
$$(\theta_{1}, \theta_{2})=\left\{\begin{array}{ll} (0,1) & \sigma(\boldsymbol{S})<\gamma_{1} \\ (0.5,0.5) & \gamma_{1}<\sigma(\boldsymbol{S})<\gamma_{2} \\ (1,0) & \gamma_{2}<\sigma(\boldsymbol{S}) \end{array}\right.$$
明显可以看出色彩更加明亮并减少了浑浊的样式,最后再和上面那个模块一样定义一个结构损失来进行约束如下式(当然这里面涉及了一个预训练的VGG来提取high-level的特征):
$$\mathcal{L}_{\text {structure}}=\left|\operatorname{VGG} _{n}\left(G\left(\boldsymbol{I} _{p}\right)\right)-\operatorname{VGG} _{n}\left(\mathcal{F} _{s t}\left(G\left(\boldsymbol{I} _{p}\right)\right)\right)\right|_1$$
3.3 Learning From the Texture Representation
(其实和超分一样的,)高频特征的恢复是主要的工作目标,但是亮度和颜色让我们可以很容易地就将真实图像和图像进行区分。因此,本文提出了一个随机颜色偏移算法\(\mathcal{F} _{rcs}\),用于从彩色图像中提取单通道的纹理特征,去除彩色图像中的色彩和亮度的因素(😄这里其实也很像超分任务里使用单通道的残差来对图像的高频部分进行恢复,VDSR)。
$$\mathcal{F}_ {r c s}\left(\boldsymbol{I}_ {r g b}\right)=(1-\alpha)\left(\beta_{1} * \boldsymbol{I}_ {r}+\beta 2 * \boldsymbol{I}{g} + \beta {3} * \boldsymbol{I}_{b}\right)+\alpha * \boldsymbol{Y}$$
其中里面的\(\boldsymbol{I}_ {r g b}\)表示三通道的RGB图像,\(\boldsymbol{I}_ {r},\boldsymbol{I}_ {g}\) 和 \(\boldsymbol{I}_ {b}\)分别表示三个不同的颜色通道,\(\boldsymbol{Y}\)表示标准方法生成的灰度图像。默认设置\(\alpha=0.8, \beta_{1}, \beta_{2}\) 和 \(\beta_{3} \sim U(-1,1)\),具体的效果可以看一下流程图里面有一定的展示。最后,构建一个判别器\(D_{t}\)来判断生成的纹理特征图是否与原图有一定的相似性,并从而引导生成器的优化过程。
$$\begin{aligned} \mathcal{L}_ {\text {surface}}\left(G, D_{s}\right) &=\log D_{s}\left(\mathcal{F}{\text {dgf}}\left(\boldsymbol{I} {c}, \boldsymbol{I}{c}\right)\right) +\log \left(1-D{s}\left(\mathcal{F}_ {\text {dgf}}\left(G\left(\boldsymbol{I}_ {p}\right), G\left(\boldsymbol{I}_{p}\right)\right)\right)\right) \end{aligned}$$
3.4 Full Model
总的损失函数如下式所示:
$$\begin{aligned} \mathcal{L}_ {\text {total}} &=\lambda_ {1} * \mathcal{L}_ {\text {surface}}+\lambda_{2} * \mathcal{L}{\text {texture}}+\lambda{3} * \mathcal{L}_ {\text {structure}}+\lambda_{4} * \mathcal{L}_ {\text {content}}+\lambda_{5} * \mathcal{L}_{t v} \end{aligned}$$
为了减少高频噪声(例如椒盐噪声)并做一些空间平滑,尝试对损失函数增加一个total-variation,设计如下:
$$\mathcal{L}_ {t v}=\frac{1}{H * W * C}\left|\nabla x\left(G\left(\boldsymbol{I} _{p}\right)\right)+\nabla _{y}\left(G\left(\boldsymbol{I} _{p}\right)\right)\right|$$
为了保证输出图像和动画图像之间的内容不存在较大的语义变化,施加一个语义损失并叠加\(\mathcal{L}_{1}\)正则化,这个稀疏地正则化可以使得局部区域能被正确地动画化,具体如下式:
$$\mathcal{L}_ {\text {content}}=\left|V G G_{n}\left(G\left(\boldsymbol{I}_ {p}\right)\right)-\operatorname{VGG}_ {n}\left(\boldsymbol{I}_{p}\right)\right|$$
为了调整输出图像地锐利度,采用了可微分地导向滤波器\(\mathcal{F}_{d g f}\)来实现样式插值如下图所示:
 这样我们就可以再不调整网络结构的前提下对图像的样式进行调整,具体的如下式:
这样我们就可以再不调整网络结构的前提下对图像的样式进行调整,具体的如下式:
$$\boldsymbol{I}_ {\text {interp}}=\delta * \mathcal{F}_ {d g f}\left(\boldsymbol{I}_ {i n}, G\left(\boldsymbol{I}_ {i n}\right)\right)+(1-\delta) * G\left(\boldsymbol{I}_{i n}\right)$$
Section 4 实验结果
这个后面其实都没啥意思了,关注的可以自己去看看论文的结果。
Demo 环节
😄 嘻嘻嘻~








总体来看涂抹感有点重,感觉不是太真实,但是人脸的效果还是不错的,个人感觉比AnimeGAN要看的舒服一点…
官方好像还提供了一个额外的人脸版本的模型,懒得去跑了…
总体来说,好像大多数做这类动画化的核心都是在调整loss方面嘛… 个人见解… 以上!
Reference
[1] Pedro F Felzenszwalb and Daniel P Huttenlocher. Efficient graph-based image segmentation. International Journal ofComputer Vision, 59(2):167–181, 2004. 2