PP-YOLO: An Effective and Efficient Implementation of Object Detector
🔗 PDF Link 🍺 Github Code
YOLO5还没来得及看,又来一个ppyolo,有点多… 😄
Section 1 介绍
开幕雷击,你们都是渣渣~
随着深度学习的进步以及深度卷积网络的发展,对象检测(Object Detection)已经取得了比较大的进展,尤其是单阶段的OD。本文在YOLO3的基础上魔改,增加一些小tricks,并评估了这些tricks所带来的性能增益。那这就有人要问了,你这个和YOLO4有啥区别呢😄?其实很简单,PPYOLO并不关注backbone的改进也不涉及过多的数据增强方面的探索。因为这两个内容都是属于独立的影响因素,与本文提到的增加的tricks并没有太多的关联性,别人也可以很容易的对这两个东西进行替换、实验。换句话说,PPYOLO有理有据的给你一些搭建基于YOLO3的OD网络的建议,该采用那些tricks,又有哪些tricks是有明显性能提升的。
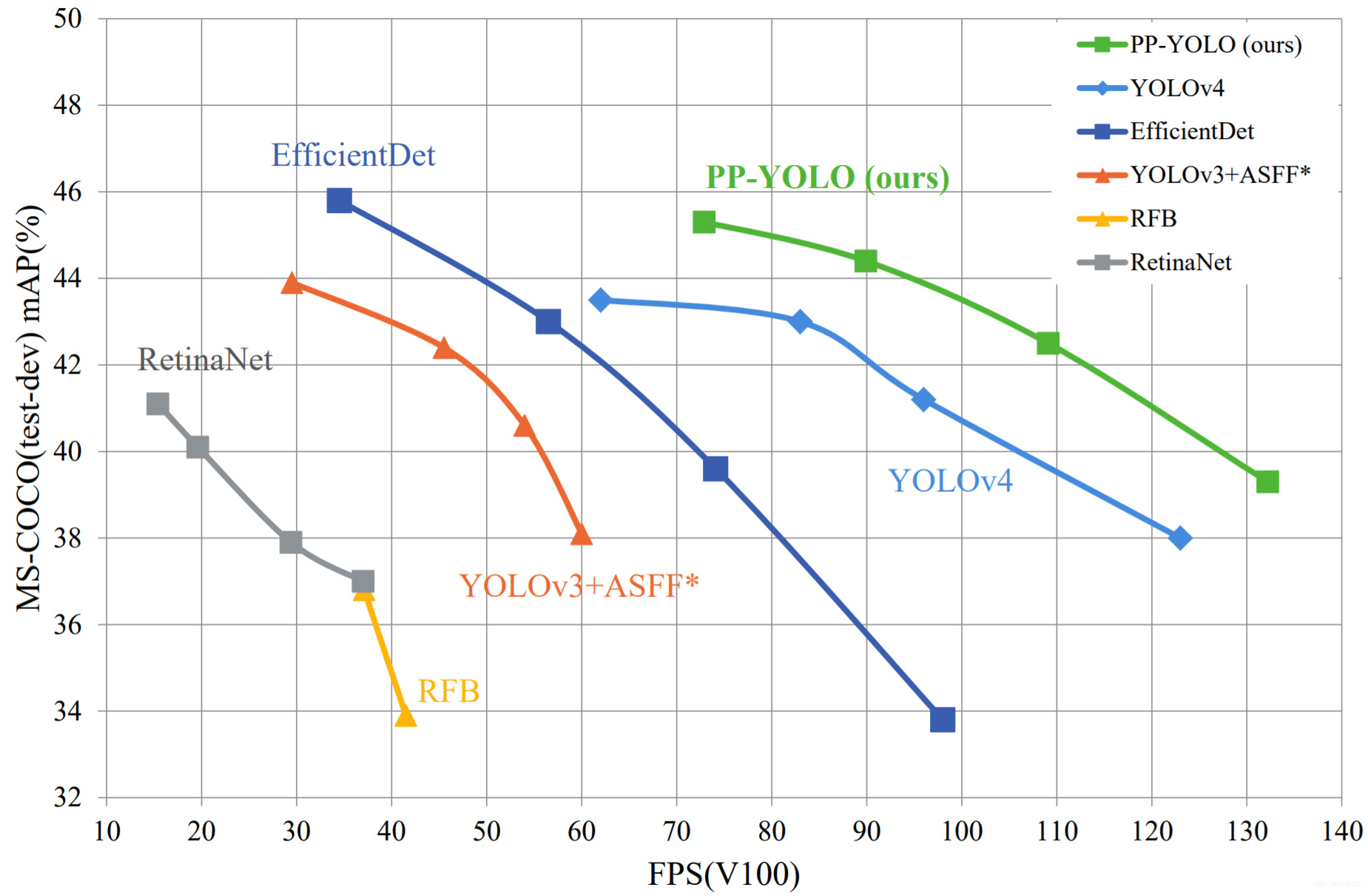
最后,PPYOLO在COCO上取得了45.2%的mAP,并且比YOLO4还快。
Section 2 相关工作
Anchor-based的方法依旧是OD的主流,它的核心在于提出了一个预定义的用于边界回归的框,这个框可以作为一个先验信息辅助回归。它主体包含了两个分支:一个是单阶段的,一个是两阶段的。除此之外,近些年来的Anchor-free的方法越来越受到欢迎,但实际上Anchor-free是一个很早就有的概念,例如YOLO1,DenseBox之类的。它也可以被分成两个不同的分支,基于Anchor-point的方法以及基于Keypoint的方法。
YOLO系列的内容在工业界被广泛使用,截止至这篇论文完成之时,更新到YOLO4。YOLO4提到了巨量的tricks分成bag of freebies和bag of specials分别用于训练阶段和测试阶段。PPYOLO则是在YOLO3的基础上加了一些tricks。
Section 3 方法
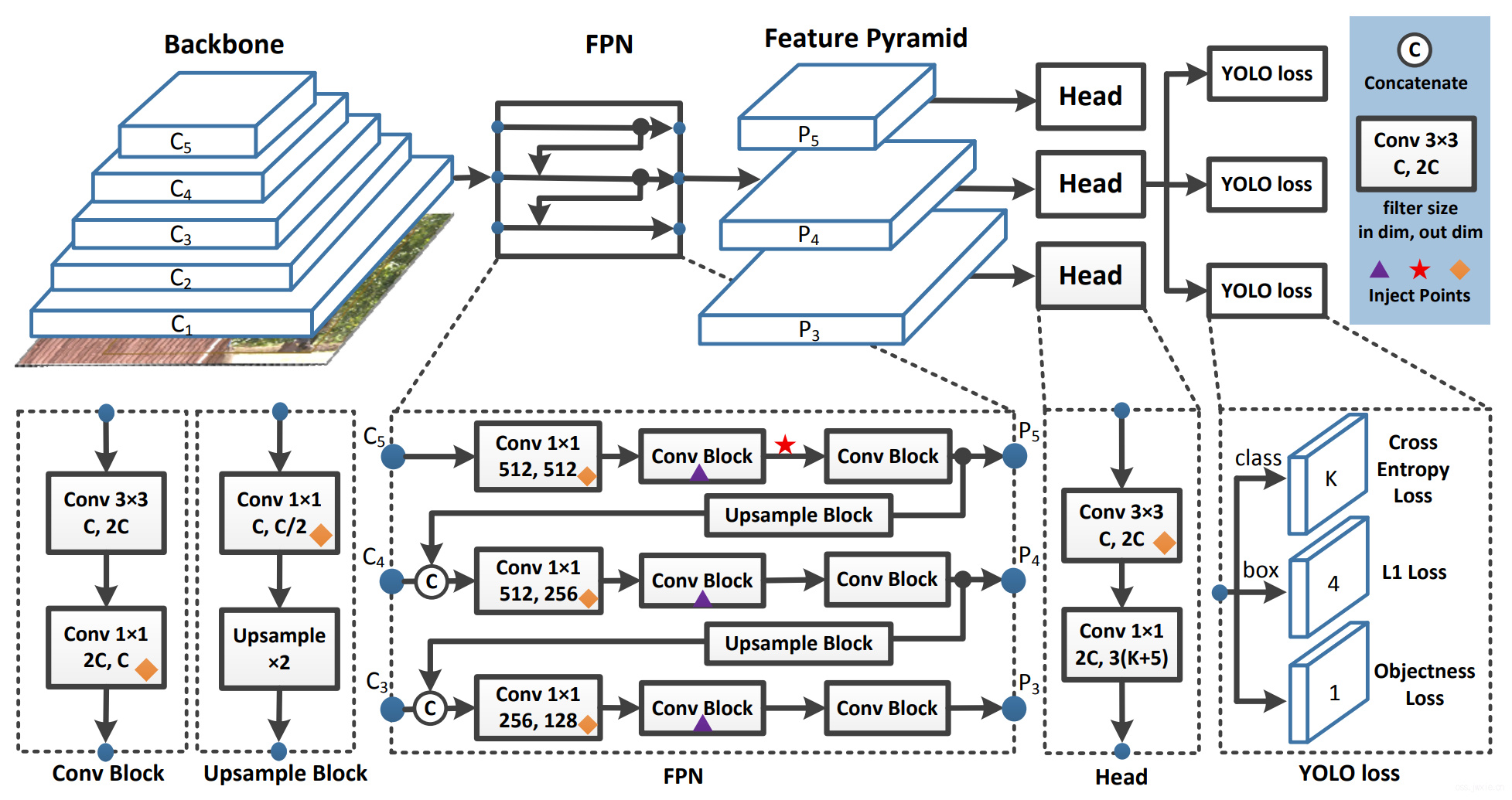
一个单阶段的Anchor based的检测模型通常是由一个骨架网络一个neck(通常是FPN),以及一个head(用于分类+定位)组成。PP-YOLO选择了ResNet50-vd-dcn作为骨架网络。
3.1 Architecture
Backbone
直接用ResNet50-vd替换掉Darknet53会导致一部分的性能损失。因此,我们尝试替换了一些ResNet中的卷积为可变形卷积(Deformable Convolution Network)。可变形卷积的效果已经被很多论文证明了其有效性,但是过多的添加DCN层会导致增加预测时间。论文这里使用的一个平衡的方案就是替换了最后一个stage的3x3卷积为DCNs。
Detection Neck
使用FPN,将backbone的3,4,5个stage的输出作为FPN的输入(图中的\(C_l\),其中\(l=3,4,5\)),输出(图中的\(P_l\),其中\(l=3,4,5\))的大小变为输入大小的一半。
Detection Head
常规来说Head的组成都是很简单的,包含两个卷积层,一个3x3和一个1x1。当输出类别是\(K\)的时候,输出的维度就是\(3(K+5)\),每一个预测的特征图上的每一个预测位置都与三个不同的anchors相关。针对每一个anchor,前\(K\)个维度确定了类别,后4个确定了bounding box的定位,最后一个确定了是否有目标。然后CE和L1用于对这些预测值计算损失
3.2 Selection of Tricks
Larger Batch Size
把batchsize从64增大到了128能取得更获得更稳定的训练和更佳的结果。
EMA
对于训练中的各种参数,指数滑动平均通常来说是有益的,对于每一个参数\(W\),EMA可以用下面式子来表示: $$W_{EMA}=\lambda W_{E M A}+(1-\lambda) W$$ 文章这里采用的\(\lambda=0.9998\)。
DropBlock
DropBlock是一种结构性的一种正则化,通常会带着特征图一起丢掉。文章在这里仅把DropBlock应用于了FPN,因为把DropBlock放在backbone上会导致性能损失,具体的网络放置位置在上图中以三角形标记出来。
IoU Loss
L1 loss被用于边界框的回归,这个很大程度上依赖IoU,但是IoU并不能直接优化mAP,因此其他的CIoU和GIoU被提出来结解决这个问题。与YOLO4不一样的是,文章并没有直接替换L1 loss+IoU loss的方案,而是增加了另一个分支来计算IoU loss(这个后面一个部分讲)。但是,文章发现采用其他的IoU方案气势上并没有太大的效果,因此直接采用Basic IoU。
IoU Aware
在yolov3中,最后的置信度由分类概率乘以目标物体得分来确定,但这没有考虑到定位的精确度。解决这个问题的方法就是增加一个额外的IoU分支来监督这部门信息,且增加的分支所造成的FLOPs基本可以忽略不计。
Grid Sensitive
在YOLO3中,标准的框中心定位坐标可以由以下的公式来进行计算 $$ \begin{array}{l} x=s \cdot\left(g_{x}+\sigma\left(p_{x}\right)\right) \end{array} $$ $$ \begin{array}{l} y=s \cdot\left(g_{y}+\sigma\left(p_{y}\right)\right) \end{array} $$ 但是由于出现了sigmoid函数,就导致了\(\sigma\left(p_{x}\right)\)这一项很难接近0或者1(进入饱和区),更大概率会落在中间(非饱和区)。为了解决这个问题,YOLO4引入了Grid Sensitive方案 $$\begin{array}{l} x=s \cdot\left(g_{x}+\alpha \cdot \sigma\left(p_{x}\right)-(\alpha-1) / 2\right) \end{array} $$ $$ \begin{array}{l} y=s \cdot\left(g_{y}+\alpha \cdot \sigma\left(p_{y}\right)-(\alpha-1) / 2\right) \end{array}$$ 其中\(\alpha=1.05\)。
Matrix NMS
受到Soft-NMS的启发,Matrix NMS从另一个视角来看了这个问题,开启了并行计算。
CoordConv
这个部分具体看一下这儿第二个小知识,见仁见智吧~
SPP
如上图所示,星号表示引入了空间金字塔池化。一个相对大kernel的池化能有效的扩充感受野。
Better Pretrained Model
使用更好的预训练模型可以获得更好的性能。
Section 4 实验
4.1 Implementation Details
不讲了,自己看。
4.2 Ablation Study
| Methods | mAP(%) | Parameters | GFLOPs | infertime | FPS | |
|---|---|---|---|---|---|---|
| A | Darknet53YOLOv3 | 38.9 | 59.13M | 65.52 | 17.2ms | 58.2 |
| B | ResNet50-vd-dcnYOLOv3 | 39.1 | 43.89M | 44.71 | 12.6ms | 79.2 |
| C | B+LB+EMA+DropBlock | 41.4 | 43.89M | 44.71 | 12.6ms | 79.2 |
| D | C+IoULoss | 41.9 | 43.89M | 44.71 | 12.6ms | 79.2 |
| E | D+IouAware | 42.5 | 43.90M | 44.71 | 13.3ms | 74.9 |
| F | E+GridSensitive | 42.8 | 43.90M | 44.71 | 13.4ms | 74.8 |
| G | F+MatrixNMS | 43.5 | 43.90M | 44.71 | 13.4ms | 74.8 |
| H | G+CoordConv | 44 | 43.93M | 44.76 | 13.5ms | 74.1 |
| I | H+SPP | 44.3 | 44.93M | 45.12 | 13.7ms | 72.9 |
| J | I+BetterImageNetPretrain | 44.6 | 44.93M | 45.12 | 13.7ms | 72.9 |
A -> B
搭建了基础版本的PP-YOLO,替换了ResNet,减少了参数,但是也降低的mAP。因此,尝试加入DCN,提升mAP到了39.1%。
B -> C
在搭建好了骨架网络之后,就可以尝试着从训练优化的地方开始改进了,首先加入的就是大batchsize和EMA,最终提升了mAP到41.1%。
C -> F
进一步地,训练网络解决了,那就涉及到了损失函数部分地改性了,这一步加入IoU Loss,IoU Aware和Grid Sensitive三个改进,分别提升了0.5%,0.6%和0.3%,mAP提升到了42.8%。
F -> G
训练完事了,那就到了后处理,理所当然把Matrix NMS加上去,获得了0.6%的mAP提升。
G -> I
到了预测的头顶了,那么不再考虑网络了,加入SPP和CoordConv到最后和最初,使得mAP提升了0.5%。
I -> J
替换了一个预训练模型获得了0.3%的mAP提升。这里把预训练模型的更新放在最后是因为分类模型的精度提升实际上并不一定能使得检测任务中也有效。
4.3 Comparison with Other State-of-the-Art De-tectors
具体的细节看表格~
| Method | Backbone | Size | FPS(V100) | \(AP\) | \(AP_{50}\) | \(AP_{75}\) | \(AP_{S}\) | \(AP_{M}\) | \(AP_{L}\) | |
|---|---|---|---|---|---|---|---|---|---|---|
| w/oTRT | withTRT | |||||||||
| RetinaNet | ResNet-50 | 640 | 37 | - | 37.0% | - | - | - | - | - |
| RetinaNet | ResNet-101 | 640 | 29.4 | - | 37.9% | - | - | - | - | - |
| RetinaNet | ResNet-50 | 1024 | 19.6 | - | 40.1% | - | - | - | - | - |
| RetinaNet | ResNet-101 | 1024 | 15.4 | - | 41.1% | - | - | - | - | - |
| EfficientDet-D0 | Efficient-B0 | 512 | 98.0+ | - | 33.8% | 52.2% | 35.8% | 12.0% | 38.3% | 51.2% |
| EfficientDet-D1 | Efficient-B1 | 640 | 74.1+ | - | 39.6% | 58.6% | 42.3% | 17.9% | 44.3% | 56.0% |
| EfficientDet-D2 | Efficient-B2 | 768 | 56.5+ | - | 43.0% | 62.3% | 46.2% | 22.5% | 47.0% | 58.4% |
| EfficientDet-D2 | Efficient-B3 | 896 | 34.5+ | - | 45.8% | 65.0% | 49.3% | 26.6% | 49.4% | 59.8% |
| RFBNet | HarDNet68 | 512 | 41.5 | - | 33.9% | 54.3% | 36.2% | 14.7% | 36.6% | 50.5% |
| RFBNet | HarDNet85 | 512 | 37.1 | - | 36.8% | 57.1% | 39.5% | 16.9% | 40.5% | 52.9% |
| YOLOv3+ASFF* | Darknet-53 | 320 | 60 | - | 38.1% | 57.4% | 42.1% | 16.1% | 41.6% | 53.6% |
| YOLOv3+ASFF* | Darknet-53 | 416 | 54 | - | 40.6% | 60.6% | 45.1% | 20.3% | 44.2% | 54.1% |
| YOLOv3+ASFF* | Darknet-53 | 608 | 45.5 | - | 42.4% | 63.0% | 47.4% | 25.5% | 45.7% | 52.3% |
| YOLOv3+ASFF* | Darknet-53 | 800 | 29.4 | - | 43.9% | 64.1% | 49.2% | 27.0% | 46.6% | 53.4% |
| YOLOv4[1] | CSPDarknet-53 | 416 | 96 | 164.0∗ | 41.2% | 62.8% | 44.3% | 20.4% | 44.4% | 56.0% |
| YOLOv4[1] | CSPDarknet-53 | 512 | 83 | 138.4∗ | 43.0% | 64.9% | 46.5% | 24.3% | 46.1% | 55.2% |
| YOLOv4[1] | CSPDarknet-53 | 608 | 62 | 105.5∗ | 43.5% | 65.7% | 47.3% | 26.7% | 46.7% | 53.3% |
| PP-YOLO | ResNet50-vd-dcn | 320 | 132.2 | 242.2 | 39.3% | 59.3% | 42.7% | 16.7% | 41.4% | 57.8% |
| PP-YOLO | ResNet50-vd-dcn | 416 | 109.6 | 215.4 | 42.5% | 62.8% | 46.5% | 21.2% | 45.2% | 58.2% |
| PP-YOLO | ResNet50-vd-dcn | 512 | 89.9 | 188.4 | 44.4% | 64.6% | 48.8% | 24.4% | 47.1% | 58.2% |
| PP-YOLO | ResNet50-vd-dcn | 608 | 72.9 | 155.6 | 45.2% | 65.2% | 49.9% | 26.3% | 47.8% | 57.2% |
Section 4 总结
没什么好提的。