MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
Section 1 介绍
目前的场景文本检测算法还存在着明显的缺陷。以EAST为例,对于横纵比变化很大的文本的检测效果很差,如下图a和b。

- EAST网络的感受野有限导致无法获取丰富的特征信息来精确地预测长文本。
- 在EAST进行文本检测过程中,NMS是通过分类的置信度(框内是否含有文本)来进行排序评分的,这个过程忽视了由于感受野受限导致的文本框质量差异(🔥应该是指的是检测质量,感觉在这里可以认为是长文本的检测框没有很厚的覆盖文本区域的意思),从而导致文字框的预测偏差。
为了解决这两个问题,文章提出了具有定位优化的Multi-Oriented Scene Text(MOST) 检测器。其中定位优化部分(Localization refinement part),包含了Text Feature Alignment Module(TFAM)以及一个Positive-Aware Non-Maximum Supression(PA-NMS)模块。前者将图像特征与粗检测结果进行对齐(🔥这句话啥意思后面就知道了),提升了定位预测层的感受野。另一方面,后者根据它们被预测的位置自适应地合并原始检测,以专注于准确的预测,而放弃不准确的预测(🔥简单来说,前者注重特征感受野增强,后者是对NMS的提升)。此外,针对小文本的检测效果,我们设计了一个Instance-waise IoU损失,保证每一个优化对象有着相同的优化权重。
四个贡献:
- 提出TFAM,动态调整感受野。
- 提出PA-NMS,通过合并可靠的预测结果来提升性能。
- 提出Instance-ware IoU损失平衡不同尺度的训练。
- 提出了MOST达到了SOTA,并有着很快的推理速度。
Section 2 相关工作
总的来说,基于深度学习的文本检测方法大致可以分为两个类别,一个是bottom-up另一个是top-down的形式。
Bottom-up方法
将文本检测的方法分成两个步骤,(1)检测基本元素;(2)将这些基本元素整合起来产生检测结果(🔥类似局部检测,然后进行融合)。大致的方案有SegLink,SegLink++,TextSnake,CRAFT,PSENet以及PAN。大多数这类方法都受限于复杂后处理方法来组合基础元素框,导致效率和推理速度的降低。
top-down方法
通常是遵循通用目标检测方法然后直接用框输出结果。这类方法大致也分为两组,一组是one-stage,另一组的2-stage。前者例如TextBoxes,EASE,TextBoxes++以及RDD直接将文本框回归计算出来,然后利用NMS优化结果。2-stage的方案利于MaskTextSpotter系列方案,则是采用了类似MaskRCNN的形式,利用区域建议网络来产生文本框然后在框里面做处理,一般这类方法后处理步骤比较简单。
与LOMO的比较
为了解决长文本检测,LOMO提出了IRM模块通过迭代优化来识别长文本。LOMO多次提取了ROI特征,构建了一个多阶段的检测器,不同于LOMO中使用ROI transform,我们提出TFAM结合可变形卷积来优化定位,获得了更高的性能以及更高的计算效率。
Section 3 方法
MOST的整体流程如下图所示

其中包含了一个ResNet-50骨架,以及一个金字塔结构,head部分包含了一个text/non-text分类分支,一个位置敏感图预测分支,一个定位分支以及一个后处理PA-NMS模块。定位分支包含了粗定位分支头、TFAM以及一个细化定位头。
3.1 Network Design
所有的分支部分的输入都是FPN特征融合后的输出,FPN内部特征数量为256。
Text/Non-Text Classification Head
经过一组Conv+BN+ReLU,特征压缩到64,利用1x1Conv+sigmoid生成分类阈值图。
Position-Sensitive Map Prediction Head
与分类分支类似,但是特征输出是4维,每一维的值为距离边框左右上下的距离。具体如下图所示

Localization Branch
包含了一个粗定位头以及一个细化检测头。首先粗检测头将会输出粗检测框,然后TFAM根据粗检测框重新调整特征感受野,产生对齐的(Aligned)特征图,然后送到细化检测头中进行框体识别。
粗、细检测模块有着类似的结构,最终输出5个维度数据,分别表示了点到框四个边界的距离以及旋转角度。
3.2 Text Feature Alignment Module(TFAM)
由于CNN感受野的限制,对于1-stage的top-down检测器,如EAST而言,很难去精确定位文本框的边界,尤其是长宽比很大或者很小的情况。LOMO提出的优化方案是渐进地使用ROI transform。但是这类多个步骤监禁地操作将会带来额外的计算量,特别是当文本实例的数据非常大的时候。
为了解决这个问题,我们提出了TFAM,具体结构如下图所示

首先利用粗检测网络的结果生成采样点,然后将这些采样点应用到DCN中,获得细化的定位特征。位置\(p_0\)的特征\(y\)可以表示为下式
$$ y\left(p_{0}\right)=\sum_{p_{n} \in \hat{R}} w\left(p_{n}\right) * x\left(p_{0}+p_{n}+\Delta p_{n}\right) $$
具体的采样点的方式有两种: 基于特征信息的采样点 实际上只需要对特征算一个卷积,卷积的结果当成DCN的偏移即可。如下式
$$ \Delta p_n = Conv(x(p_0)) $$ 基于位置信息的采样点 $$ \Delta p_{n}=\Gamma\left(\hat{d_{c} 0}, p_{0}\right) $$ 🔥这里属实没看明白是咋处理的,也没看到有代码,持有疑问中。 其中\(\hat{d_{c} 0}\)表示\(p_0\)位置上的粗检测框,\(\Gamma\)函数表示偏差的是计算是粗检测框的中的随机采样点。需要保证这些点是在粗检测框之中。
通过采用基于定位的采样方法,TFAM可以生成与粗略检测一致的特征,细定位头可以进一步使用这些特征来生成比粗略检测更好地包围文本区域的精细的检测结果。
3.3 Position-Aware Non-Maximum Supression
NMS in EAST
EAST提出了位置感知NMS来融合所有的阳性检测框。对比传统的NMS,位置感知NMS能够在更短的时间内生成更加稳定的结果,具体可以分为两个步骤,权重融合+标准NMS。在权重融合的过程中按行迭代进行融合。给定两个框\(p\)和\(q\)以及对应的分类得分\(S(p)\)和\(S(q)\),权重融合可以被定义为如下式
$$ m_{i}=\frac{\left(S(p) p_{i}+S(q) q_{i}\right)}{S(m)}, \quad i=1, \cdots, 4; S(m)=S(p)+S(q) $$
第一行表示新生成的框的四个角点的位置,第二行表示新生成的框的置信度。
Proposed Position-Aware NMS
实际上越靠近边框边缘的点越能精确的预测文本框的位置,如下图
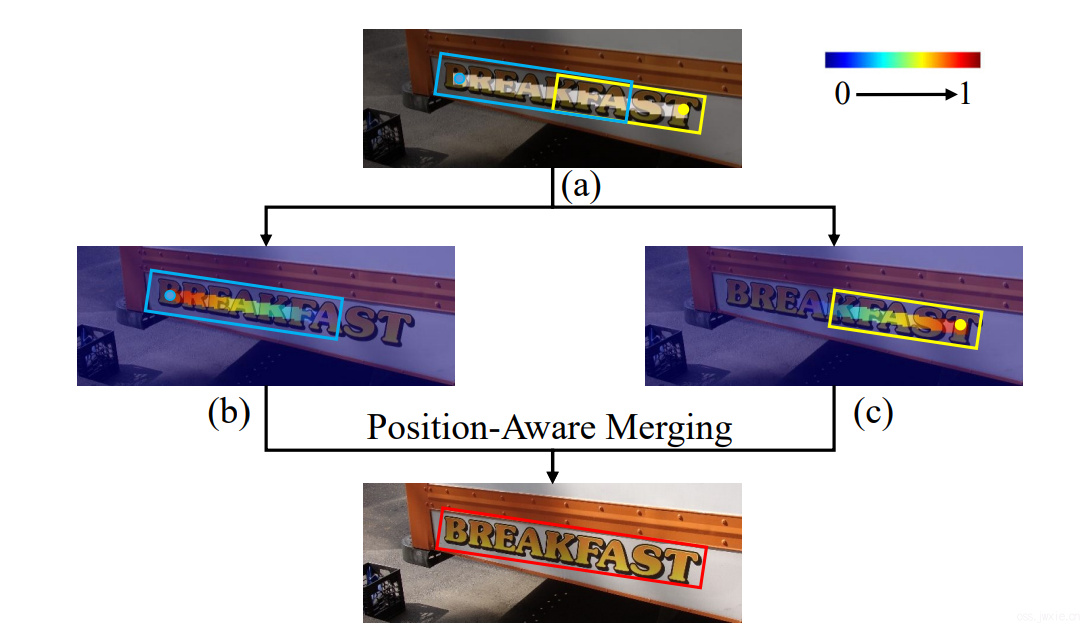
我们提出了Position-Aware NMS,通过位置敏感特征图能够保留正确的部分并去除不正确部分,其中位置敏感特征见Position-Sensitive Map Prediction Head章节的图c-f。
给定两个框\(p\)和\(q\)以及对应的分类得分\(S(p)\)和\(S(q)\),权重融合可以被定义为如下式 $$ \begin{aligned} m_{i}(x) &=\left(L(p) p_{i}(x)+L(q) q_{i}(x)\right) / L(m), i=1,4 \\ m_{j}(x) &=\left(R(p) p_{j}(x)+R(q) q_{j}(x)\right) / R(m), j=2,3 \\ m_{k}(y) &=\left(T(p) p_{k}(y)+T(q) q_{k}(y)\right) / T(m), k=1,2 \\ m_{l}(y) &=\left(B(p) p_{l}(y)+B(q) q_{l}(y)\right) / B(m), l=3,4 \\ \Psi(m) &=\Psi(p)+\Psi(q), \quad \Psi \in{L, R, T, B} \end{aligned} $$
PA-NMS使用了position-aware置信度而不是分类分支,能够更精确地定位文本边界。
3.4 Label Generation
我们采用了和EAST同样地方式生成score map和geometry map。 对于每一文本实例,位置敏感特征图被下式定义 \[ \begin{aligned} & F(i)=\left\{\begin{array}{ll} 1 - \frac{\operatorname{Dist}(i, f)-\min (D_{f})}{d_{f}-\min (D_{f})}, & \text { if } \operatorname{Dist}(i, f)<d_{f} \\ 0, & \text { Otherwise }\end{array} \right. \\ & d_{f}=\alpha * \left(\max \left(D_{f}\right)-\min \left(D_{f}\right)\right)+\min \left(D_{f}\right) \\ & D_{f}={\operatorname{Dist}(i, f) \mid i \in P} \end{aligned} \]
其中\(f\)表示文本框四条中的一条,\(F\)表示对应的位置敏感特征图。\(d_f\)表示距离阈值,当前\(\alpha\)取值为0.75。
3.5 Instance-wise IoU loss
EAST中对于几何框的训练采用了IoU损失,但是对于大文本目标有着比小文本目标更多的阳性样本,这使得优化偏向于大目标,为了平衡小目标的损失,提出的损失函数如下式。每一个阳性框内的损失值都会被框体内的阳性框数量进行归一化,因此来保证每一个框的损失都会被平等地对待。
$$ L_{ins-iou} = - \frac{1}{N_t} \sum_{k \in S_j} logIoU(\hat d_{jk}, d^{*}_{jk}) $$
3.6 Optimization
损失函数被定义为如下式 $$ L = L_s + \lambda_{gc}L_{gc} + \lambda_{gr}L_{gr} + \lambda_{p}L_p $$
其中各个损失分别表示分类损失,粗定位模块几何特征图,细定位模块特征图以及位置敏感特征图,所有的调节参数\(\lambda\)在我们的实验中都设置为1。注意仅计算了正样本的额\(L_{gc}, L_{gr}, L_{p}\),记为\(\Omega\)。
Loss for Score Map
使用BCE损失来计算概率图的预测结果,记为\(L_s\),并结合OHEM,其中正负样本的比例设置为1:3。
Loss for Geometry Maps
角度的损失定义为如下式
$$ L_{\theta} = \frac{1}{|\Omega|}\sum_{i \in \Omega} 1 - cos (\hat \theta_i - \theta_i^*) $$
其中,\(\hat \theta_i, \theta_i^*\)分别代表了预测的旋转角度以及\(\Omega\)中第\(i\)个样本对应的标签。
\(L_{gc}, L_{gr}\)的形式和\(L_{g}\)的形式保持一致,具体如下式所示:
$$ L_g = L_{iou} + \lambda_i L_{ins_iou} + \lambda_{\theta} L_{\theta} $$
两个\(\lambda\)的值分别为1和20。
Loss for Position-sensitive Maps
针对\(L_p\)采用了Smooth-L1损失,具体如下式
$$ L_p = \frac{1}{4|\Omega|} \sum_{i \in \Omega} \sum_{\Psi \in { L,R,T,B }} SmoothedL1(\hat \Psi_i - \Psi^*_i) $$
符号表示大致与前面相似。
Section 4. 实验
这部分就不看了,实验细节,主要看消融实验部分是相对有意思的地方,这里也不细说,有兴趣可以关注一下。
Section 5. 结论
总结。