Multi-Stage Progressive Image Restoration
Section 1 介绍
图像恢复是一个从低质量的图像恢复出高清图像的任务。典型的低质量因素有噪声,模糊,水滴噪声,雾噪声等。这是一个高度病态的问题,因为本质上对一张输入的低质量图像存在无限的可行解。为此,许多工作通过增加人工设计的图像先验信息,同时限制解空间的大小为自然图像来解决上述问题。但是设计这种先验本身就已经是一个很具有挑战性的任务了,而且很多时候这种设计的先验的泛化性能不佳。为了改进这个问题,近期的SOTA的方案使用CNNs从大量的数据中学习捕获自然图像的统计先验信息。
基于CNNs的方法的性能表现很大程度上取决于模型结构的设计。大量适用于图像恢复的网络结构模块一集函数单元被设计出来用于提升模型性能,如残差学习,空洞卷积,注意力机制,稠密连接,编解码结构等。然而,几乎所有的这些方法在提出时候(针对低级别的视觉任务),都基于单阶段设计。与之相反,在高阶的视觉任务中,多阶段的网络模型的显示了更高的效率,例如姿态估计,场景解析以及动作分割。
近期,有一些工作尝试将多阶段的设计引入到去模糊,图像去雨任务中。文章分析了这些方法,找出了限制性能提升的瓶颈点。首先,目前的多阶段方案大都采用了编解码结构,这种方式对大面积的周便信息的编码很有效,但是对于图像空间信息的保留能力缺缺;或使用单尺度的方案,单尺度仅能提供完整的空间信息但是缺少可靠的语义输出。我们尝试将这两种设计整合了起来,变为一个多阶段的结构。其次,我们发现简单地把第一个阶段地结果传递到第二个阶段作为输入本身并不能取得最优的结果(次优)。第三,在图像恢复任务中,给多个阶段提供GT监督非常重要。最后,在多阶段的处理中,在编码解码结构中通过一定的机制将初始的特征图传递给后面的阶段有利于保留周围的纹理特征。
我们提出了一直用多阶段的渐进式图像恢复结构MPRNet,有以下几个主要的组成部分:
- 前面的stage采用了一个编码解码结构来学习多尺度的纹理信息,而最后的一个stag则在原始的图像尺寸上进行,用以保留完整的空间细节。
- 一个监督的注意力模块(supervised attention module)被插入到任两个stage之间来促成渐进式的学习。通过与GT的对比,产生的监督信息,SAM模块会尽可能地探索前一个模块的输出来产生注意力图,并根据这个注意力图来实现对前面stage的参数优化,避免传入到下一个stage。
- 一个跨stage的特征融合机制CSFF(cross-stage feature fusion)被添加以实现多尺度的上下文特征在多个stage之间的传递。同时,这个模块是的多个stages之间的信息流动更便捷了,并是的多阶段网络的优化过程更加稳定。
主要工作贡献:
- 一个新颖的基于多阶段方法,生成具有丰富上下文以及精确的空间信息的能力。基于其多阶段的本质,我们提出的框架将图像恢复的任务拆分为了几个子问题来进行渐进式的恢复。
- 一个有效的监督注意力模块,在多阶段任务中,能在达到下一个阶段之前更有效地利用当前恢复的图像数据。
- 提出了一个跨阶段的多尺度特征融合方法。
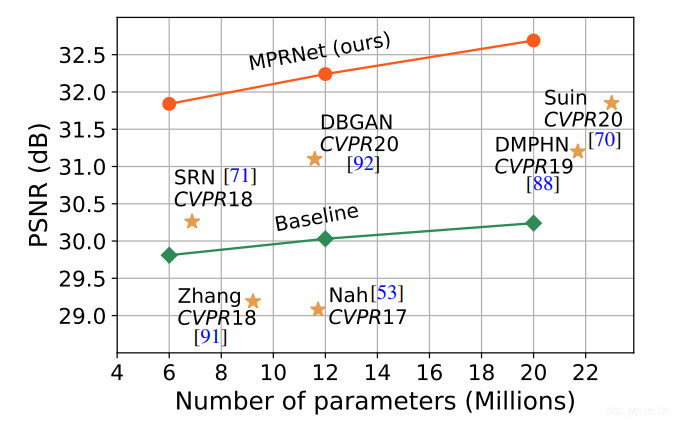
- 我们在10个生成数据集以及真实数据集上,展示了MPRNet的性能,取得了SOTA(且在许多任务中有效,复杂度也低,如下图)。同时还做了一些消融实验、量化以及泛化测试。
Section 2 相关工作
早期的图像恢复任务基于total variation(❓),稀疏编码,自相似度,梯度先验等。近期基于CNN的方法取得了SOTA,从结构设计的角度看,和谐方法大致地可以分为单阶段和多阶段。
Single-Stage Approachs
目前大多数的基于CNN的方法都是单阶段设计,且里面的模块都是为了高层视觉任务所设计。例如残差学习被用于去噪,去雨,去模糊等场景。与之相似,编解码结构,空洞卷积经常被用于提取多尺度的信息。还有一些方法尝试了稠密连接。
Multi-Stage Approaches
多阶段的方法则是尝试采用渐进式的方法,在每一个stage都采用一个轻量级的子网络来实现。这种设计方法将图像恢复的任务分解为了多个简单的子任务来进行,因此会相对更为有效。但是,常规的方法使用同样的子网络并不是一个最好的方案,详见实验4。
Attention
注意力机制被大量地使用与分类、分割、检测等任务中。在图像恢复任务中,例子比比皆是。核心的思想在于注意力机制能够捕捉空间、通道上长距离的相互依赖关系。
Section 3 方法
主要的框架结构如下图所示。
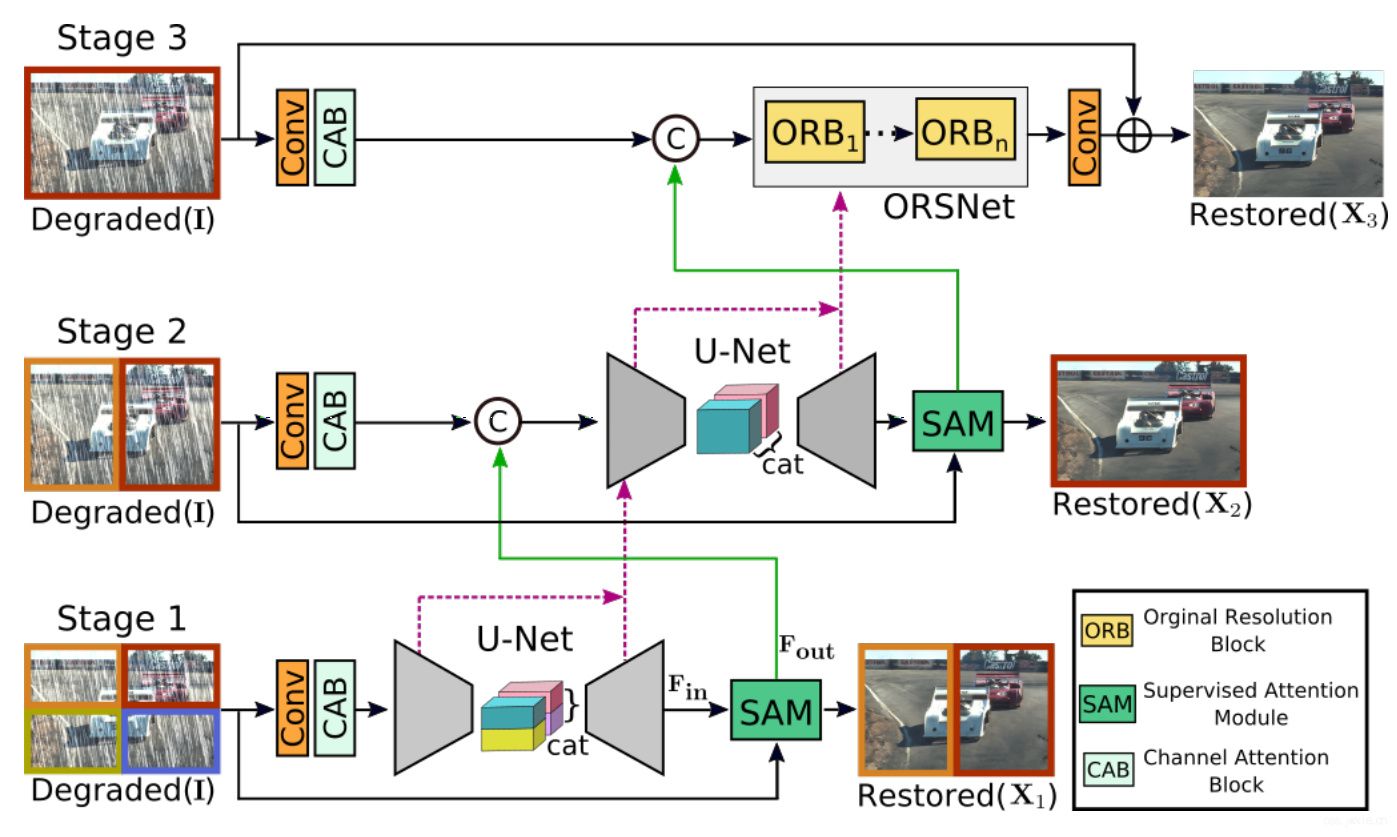
主要包含了三个stages,前两个是基于编解码结构的自网络,利用其较大的感受野用于学习丰富的图像上下文信息。此外,由于图像恢复任务是一个位置敏感的任务(输入输出的像素对保持一致),最后一个stage则采用了原始尺寸的图像数据作为输入,用以保留想要留下的纹理信息。
相对于直接级联不同的stages,我们采用了一个CAB模块来对接不同的stages。此外,还引入了CSFF机制。前面的stage的中间多尺度语境化特征有助于巩固后一个子网络的的中间层特征。
尽管MPRNet堆叠了多个stages,但是每一个stage都能获取到原始的输入图像数据。与近期的图像恢复方法相似,我们采用了多补丁的层级结构,将数据按照非重叠的形式分块:4个块送入第一个stage,2个块送入第二个stage,原始不分块图像送入到最后一个stage。
在任何一个指定的stage\(S\),相对于直接预测恢复的图像\(X_S\),我们提出的模型选择预测残差图像\(R_S\),因此真实的图像实际为输入图像\(I\)与残差图像的和: \(X_S=I+R_S\)。我们使用如下的损失函数来对MPRNet进行优化: $$ \mathcal{L}=\sum_{S=1}^{3}\left[\mathcal{L}_{\text {char }}\left(\mathbf{X}_{S}, \mathbf{Y}\right)+\lambda \mathcal{L}_{\text {edge }}\left(\mathbf{X}_{S}, \mathbf{Y}\right)\right] $$ 其中\(Y\)表示GT数据,\(\lambda\)被设置为0.05,\(\mathcal{L}_{char}\)表示Charbonnier损失: $$ \mathcal{L}_{\text {char }}=\sqrt{\left|\mathbf{X}_{S}-\mathbf{Y}\right|^{2}+\varepsilon^{2}} $$ 其中\(\varepsilon\)根据经验设置为\(10^{-3}\)。此外,\(\mathcal{L}_{edge}\)表示边缘损失:
$$ \mathcal{L}_{\text {edge }}=\sqrt{\left|\Delta\left(\mathbf{X}_{S}\right)-\Delta(\mathbf{Y})\right|^{2}+\varepsilon^{2}} $$ 其中,\(\Delta\)表示拉普拉斯算子(用于提取边缘)。
后面我 们将会逐个介绍我们方法的关键的组成部分。
3.1 Complementary Feature Processing
目前的用与图像恢复单阶段CNNs方法大都使用如下的一个设计方案:
- 编解码结构
- 单尺度特征
Complementary Feature Processing
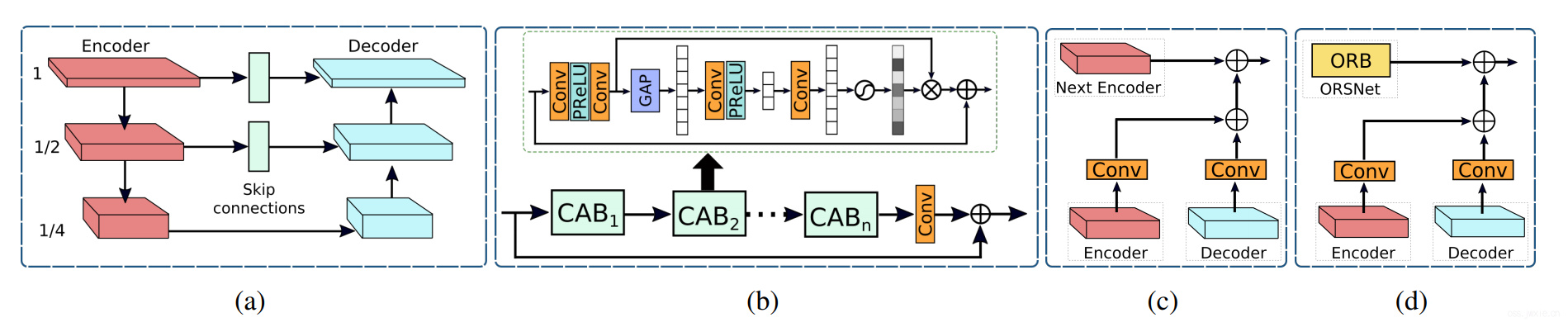
上图(a)展示了我们的编解码结构子网络,基于标准的UNet,依次添加了一下的一些模块。首先我们添加了CABs用于提取不同不同层次的特征,见上图b;其次,在UNet的跳跃连接部分,我们也加入了CAB;最后,除了使用转置卷积来提升分辨率,我们采用了上线性插值上采样+卷积的形式,这能减少通常由于转置卷积导致的棋盘伪影。
Original Resolution Subnetwork
为了保留精致的细节信息,我们在最后一个stage引入了使用原始图像尺寸的子网络(ORSNet)。最后一个stage没有采用任何的下采样操作,其中包含了多个原始分辨率的blocks(ORBs),每一个都保留了CAB模块,详见上图b。
3.2 Cross-stage Feature Fusion
在我们的结构中,我们在两个编解码模块之间(上图c),ORSNet和编解码模块之间(上图d)使用了CSFF模块。注意一个stage之后的特征首先需要经过1x1的卷积之后才会被传递给下一个stage进行整合。CSFF的引入有几个有点。首先,他使得网络更稳定,更不容易因为重复使用上下采样儿导致信息丢失。此外,单stage的多尺度特征能够帮助丰富下一个stage的特征。第三,CSFF的引入使得网络的优化更加稳定,因为其促进的信息的流动。
3.3 Supervised Attention Module
近期用于图像恢复的多阶段网络大都为在每一个stage预测图像,然后将这个结果送入到下一个连续的stage。我们引入了一个监督注意力模块(CAM)来连接两个不同的stage,这个模块的引入显著提升了性能。
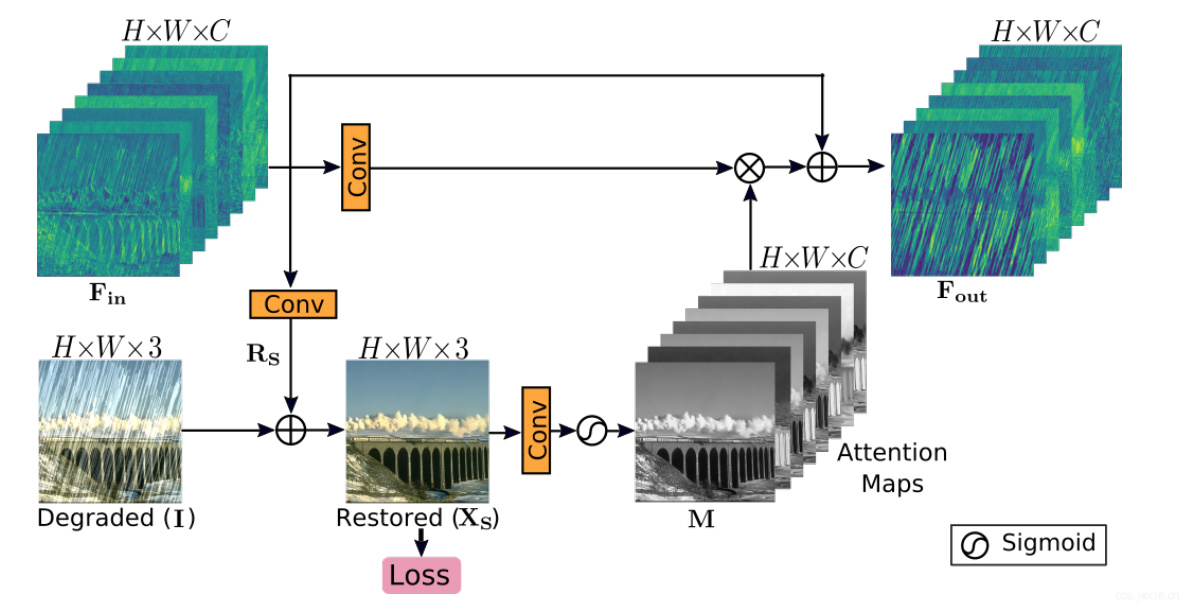
CAM的结构如上图所示,该结构的贡献主要分为两步。首先,它提供了一个GT监督信号,这个信号对于渐进式的图像恢复有意义。此外,这个局部监督信号的引入使得只有有效的信息会被送入到下一个stage。
如上图所示,SAM将上一个stage的输入\(\mathbf{F}_{\mathbf{i n}} \in \mathbb{R}^{H \times W \times C}\)经过一个1x1的卷积生成 \(\mathbf{R}_{S} \in \mathbb{R}^{H \times W \times 3}\)。然后将残差图像与低质量的图像相叠加生成恢复图像\(\mathbf{X}_{S} \in \mathbb{R}^{H \times W \times 3}\)。然后使用这个恢复的图像,通过1x1的卷积和一个sigmoid函数生成一些注意力图\(\mathbf{M} \in \mathbb{R}^{H \times W \times C}\),然后这些注意力图会被用于重构前一个stage的输出特征(SAM模块的输入\(\mathbf{F}_{\mathbf{i n}}\)),生成注意力引导的特征\(\mathbf{F}_{\mathbf{o u t}}\)送入到下一个stage。
Section 4 实验与分析
在多个任务上评估的我们的方法,a)图像去雨,b)图像去模糊,c)图像去噪,共涵盖10个不同的数据集。
4.1 Datasets and Evaluation Protocol
使用PSNR和SSIM来进行对比。后面就不写了,结果自己看表。
| Tasks | Deraining | Deblurring | Denoising | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datasets | Rain14000 | Rain1800 | Rain800 | Rain100H | Rain100L | Rain1200 | Rain12 | GoPro | HIDE | RealBlur | SIDD | DND |
| TrainSamples | 11200 | 1800 | 700 | 0 | 0 | 0 | 12 | 2103 | 0 | 0 | 320 | 0 |
| TestSamples | 2800 | 0 | 100 | 100 | 100 | 1200 | 0 | 1111 | 2025 | 1960 | 40 | 50 |
| TestsetRename | Test2800 | - | Test100 | Rain100H | Rain100L | Test1200 | - | - | - | - | - | - |
Image Deraining
Image Deblurring
Image Denoising
4.2 Implementation Details
我们的MPRNet是端到端训练的且不需要与训练。为不同的任务独立训练模型。我们采用了2CABs在每个尺度的编解码器,使用了2x2和stride为2的max-pooling。在最后一个stage中,采用了包含3个ORBs的ORSNet,其中每个ORB又使用了8个CABs。考虑到任务的复杂度,我们缩放了网络的宽度,去雨用了40个通道,去噪用了80个通道,去模糊用了96个通道。网络都是在256x256的patch上进行训练,batchsize为16,总共训练\(4 \times 10^5\)轮。水平和纵向的反转被随机的应用作为数据增强方法。使用了Adam优化器,初始学习率为\(2 \times 10^{-4}\),使用cosine annealing策略最终减小到\(1 \times 10^{-6}\)。
4.3 Image Deraining Results
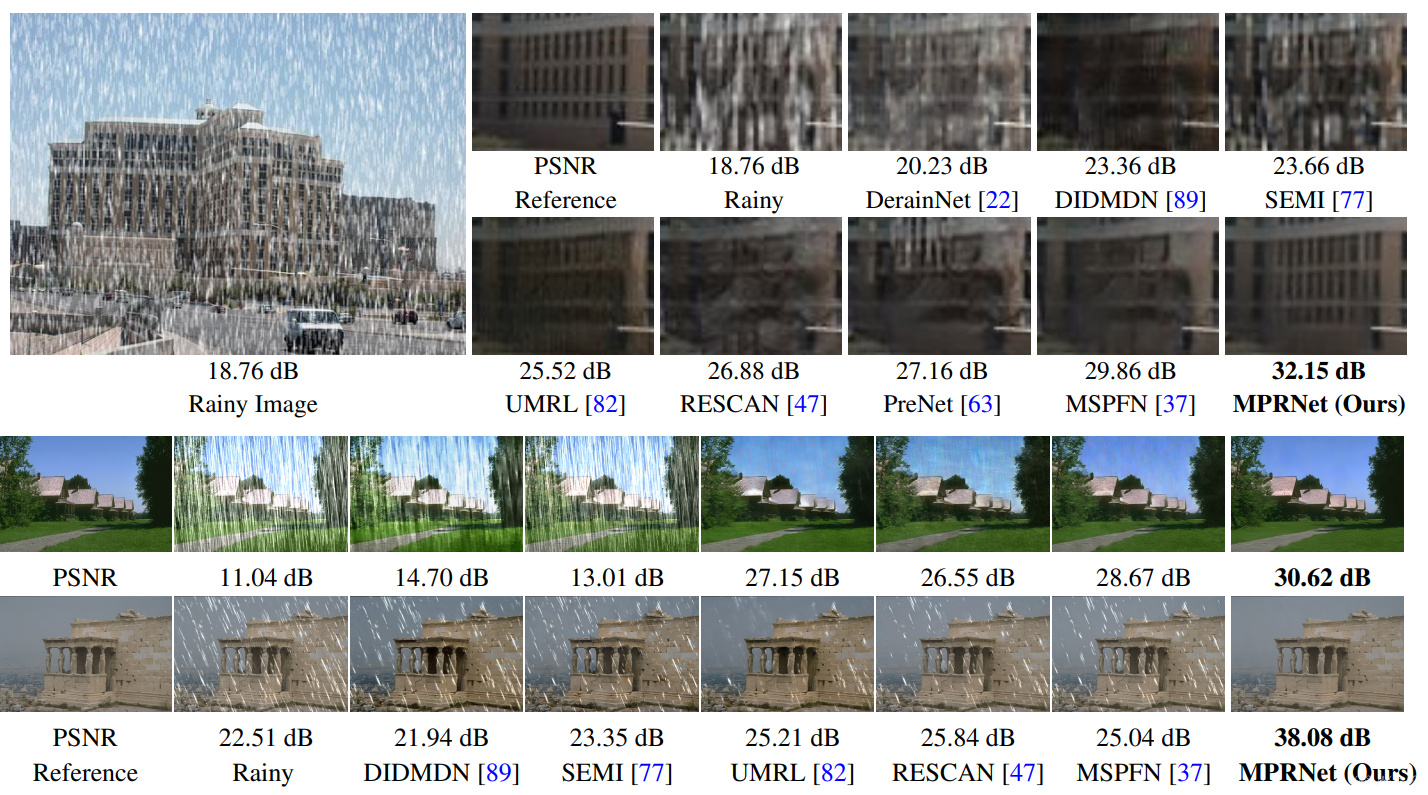
| Test100 | Rain100H | Rain100L | Test2800 | Test1200 | Average | Average | Average | Average | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | ||
| DerainNet[22] | 22.77 | 0.810 | 14.92 | 0.592 | 27.03 | 0.884 | 24.31 | 0.861 | 23.38 | 0.835 | 22.48 | (69.3%) | 0.796 | (61.3%) |
| SEMI[77] | 22.35 | 0.788 | 16.56 | 0.486 | 25.03 | 0.842 | 24.43 | 0.782 | 26.05 | 0.822 | 22.88 | (67.8%) | 0.744 | (69.1%) |
| DIDMDN[89] | 22.56 | 0.818 | 17.35 | 0.524 | 25.23 | 0.741 | 28.13 | 0.867 | 29.65 | 0.901 | 24.58 | (60.9%) | 0.77 | (65.7%) |
| UMRL[82] | 24.41 | 0.829 | 26.01 | 0.832 | 29.18 | 0.923 | 29.97 | 0.905 | 30.55 | 0.910 | 28.02 | (41.9%) | 0.88 | (34.2%) |
| RESCAN[47] | 25.00 | 0.835 | 26.36 | 0.786 | 29.80 | 0.881 | 31.29 | 0.904 | 30.51 | 0.882 | 28.59 | (37.9%) | 0.857 | (44.8%) |
| PreNet[63] | 24.81 | 0.851 | 26.77 | 0.858 | 32.44 | 0.950 | 31.75 | 0.916 | 31.36 | 0.911 | 29.42 | (31.7%) | 0.897 | (23.3%) |
| MSPFN[37] | 27.50 | 0.876 | 28.66 | 0.860 | 32.40 | 0.933 | 32.82 | 0.930 | 32.39 | 0.916 | 30.75 | (20.4%) | 0.903 | (18.6%) |
| MPRNet(Ours) | 30.27 | 0.897 | 30.41 | 0.890 | 36.40 | 0.965 | 33.64 | 0.938 | 32.91 | 0.916 | 32.73 | (0.0%) | 0.921 | (0.0%) |
4.4 Image Deblurring Results

| GoPro | HIDE | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | ||||
| Xu etal.[80] | 21.00 | (73.9%) | 0.741 | (84.2%) | - | - | - | - |
| Hyun etal.[36] | 23.64 | (64.6%) | 0.824 | (76.7%) | - | - | - | - |
| Whyte etal.[78] | 24.60 | (60.5%) | 0.846 | (73.4%) | - | - | - | - |
| Gong etal.[27] | 26.40 | (51.4%) | 0.863 | (70.1%) | - | - | - | - |
| DeblurGAN[42] | 28.70 | (36.6%) | 0.858 | (71.1%) | 24.51 | (52.4%) | 0.871 | (52.7%) |
| Nah etal.[53] | 29.08 | (33.8%) | 0.914 | (52.3%) | 25.73 | (45.2%) | 0.874 | (51.6%) |
| Zhang etal.[91] | 29.19 | (32.9%) | 0.931 | (40.6%) | - | - | - | - |
| DeblurGAN-v2[43 | ] 29.55 | (30.1%) | 0.934 | (37.9%) | 26.61 | (39.4%) | 0.875 | (51.2%) |
| SRN[71] | 30.26 | (24.1%) | 0.934 | (37.9%) | 28.36 | (25.9%) | 0.915 | (28.2%) |
| Shen etal.[69] | - | - | - | - | 28.89 | (21.2%) | 0.93 | (12.9%) |
| Gao etal.[25] | 30.90 | (18.3%) | 0.935 | (36.9%) | 29.11 | (19.2%) | 0.913 | (29.9%) |
| DBGAN[92] | 31.10 | (16.4%) | 0.942 | (29.3%) | 28.94 | (20.8%) | 0.915 | (28.2%) |
| MT-RNN[58] | 31.15 | (16.0%) | 0.945 | (25.5%) | 29.15 | (18.8%) | 0.918 | (25.6%) |
| DMPHN[88] | 31.20 | (15.5%) | 0.94 | (31.7%) | 29.09 | (19.4%) | 0.924 | (19.7%) |
| Suin etal.[70] | 31.85 | (8.9%) | 0.948 | (21.2%) | 29.98 | (10.7%) | 0.93 | (12.9%) |
| MPRNet(Ours) | 32.66 | (0.0%) | 0.959 | (0.0%) | 30.96 | (0.0%) | 0.939 | (0.0%) |
| RealBlur-R | RealBlur-J | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM | ||||
| Hu etal.[33] | 33.67 | (23.4%) | 0.916 | (42.9%) | 26.41 | (23.2%) | 0.803 | (35.5%) |
| Nah etal.[53] | 32.51 | (33.0%) | 0.841 | (69.8%) | 27.87 | (9.1%) | 0.827 | (26.6%) |
| DeblurGAN[42] | 33.79 | (22.4%) | 0.903 | (50.5%) | 27.97 | (8.1%) | 0.834 | (23.5%) |
| Pan etal.[56] | 34.01 | (20.4%) | 0.916 | (42.9%) | 27.22 | (15.7%) | 0.79 | (39.5%) |
| Xu etal.[80] | 34.46 | (16.2%) | 0.937 | (23.8%) | 27.14 | (16.4%) | 0.83 | (25.3%) |
| DeblurGAN-v2[43] | 35.26 | (8.1%) | 0.944 | (14.3%) | 28.7 | (0.0%) | 0.866 | (5.2%) |
| Zhang etal.[91] | 35.48 | (5.7%) | 0.947 | (9.4%) | 27.8 | (9.8%) | 0.847 | (17.0%) |
| SRN[71] | 35.66 | (3.7%) | 0.947 | (9.4%) | 28.56 | (1.6%) | 0.867 | (4.5%) |
| DMPHN[88] | 35.7 | (3.3%) | 0.948 | (7.7%) | 28.42 | (3.2%) | 0.86 | (9.3%) |
| MPRNet(Ours) | 35.99 | (0.0%) | 0.952 | (0.0%) | 28.7 | (0.0%) | 0.873 | (0.0%) |
| DeblurGAN-v2[43] 36.44 | 36.44 | (28.1%) | 0.935 | (56.9%) | 29.69 | (21.2%) | 0.87 | (40.0%) |
| SRN[71] | 38.65 | (7.3%) | 0.965 | (20.0%) | 31.38 | (4.3%) | 0.909 | (14.3%) |
| MPRNet(Ours) | 39.31 | (0.0%) | 0.972 | (0.0%) | 31.76 | (0.0%) | 0.922 | (0.0%) |
4.5 Image Denoising Results
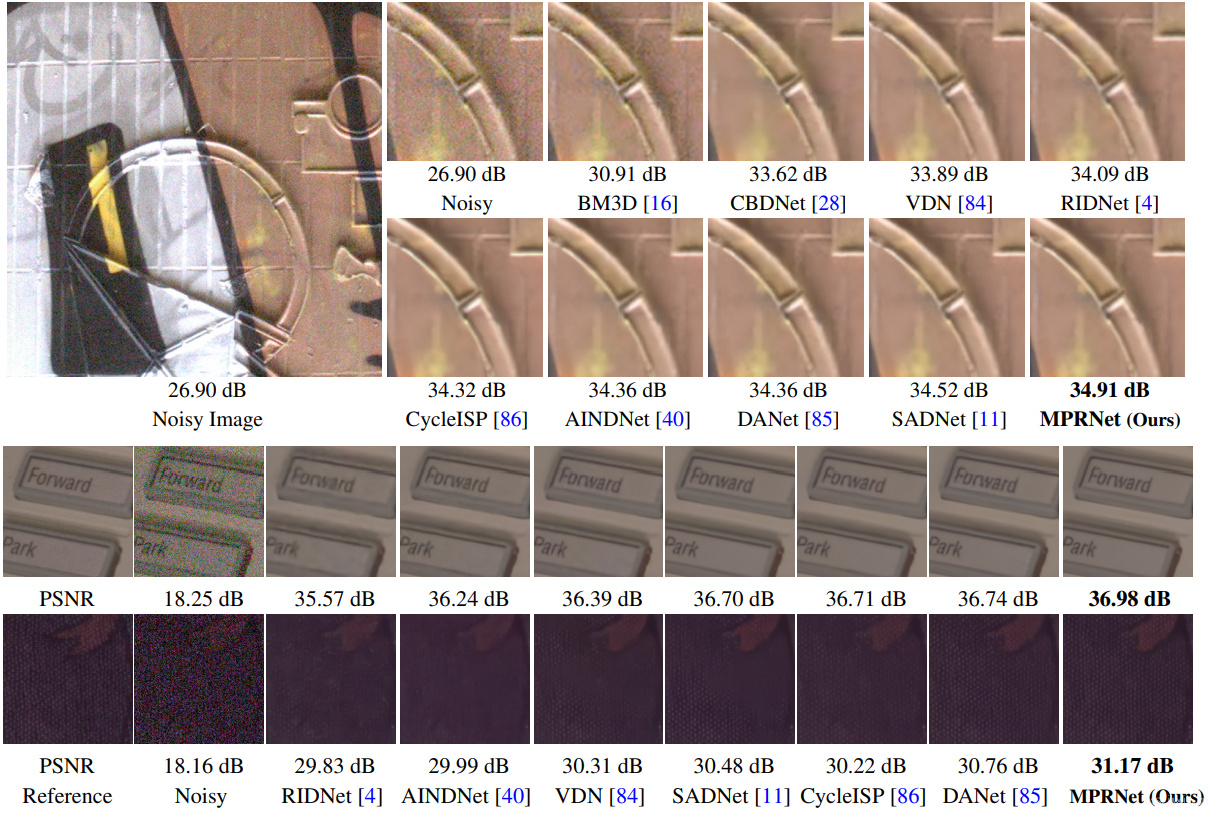
| SIDD | DND | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | ||||
| DnCNN[93] | 23.66 | (84.2%) | 0.583 | (89.9%) | 32.43 | (57.2%) | 0.790 | (79.1%) |
| MLP[9] | 24.71 | (82.2%) | 0.641 | (88.3%) | 34.23 | (47.3%) | 0.833 | (73.7%) |
| BM3D[16] | 25.65 | (80.2%) | 0.685 | (86.7%) | 34.51 | (45.6%) | 0.851 | (70.5%) |
| CBDNet* [28] | 30.78 | (64.2%) | 0.801 | (78.9%) | 38.06 | (18.2%) | 0.942 | (24.1%) |
| RIDNet* [4] | 38.71 | (10.9%) | 0.951 | (14.3%) | 39.26 | (6.0%) | 0.953 | (6.4%) |
| AINDNet* [40] | 38.95 | (8.4%) | 0.952 | (12.5%) | 39.37 | (4.8%) | 0.951 | (10.2%) |
| VDN[84] | 39.28 | (4.8%) | 0.956 | (4.6%) | 39.38 | (4.7%) | 0.952 | (8.3%) |
| SADNet* [11] | 39.46 | (2.8%) | 0.957 | (2.3%) | 39.59 | (2.4%) | 0.952 | (8.3%) |
| DANet+* [85] | 39.47 | (2.7%) | 0.957 | (2.3%) | 39.58 | (2.5%) | 0.955 | (2.2%) |
| CycleISP* [86] | 39.52 | (2.2%) | 0.957 | (2.3%) | 39.56 | (2.7%) | 0.956 | (0.0%) |
| MPRNet(Ours) | 39.71 | (0.0%) | 0.958 | (0.0%) | 39.80 | (0.0%) | 0.954 | (4.4%) |
4.6 Ablation Studies
| #Stages | StageCombination | SAM | CSFF | PSNR |
|---|---|---|---|---|
| 1 | U-Net(baseline) | - | - | 28.94 |
| 1 | ORSNet(baseline) | - | - | 28.91 |
| 2 | U-Net+U-Net | ✗ | ✗ | 29.4 |
| 2 | ORSNet+ORSNet | ✗ | ✗ | 29.53 |
| 2 | U-Net+ORSNet | ✗ | ✗ | 29.7 |
| 3 | U-Nets+ORSNet | ✗ | ✗ | 29.86 |
| 3 | U-Nets+ORSNet | ✗ | ✓ | 30.07 |
| 3 | U-Nets+ORSNet | ✗ | ✗ | 30.31 |
| 3 | U-Nets+ORSNet | ✓ | ✓ | 30.49 |
Section 5 高效的图像恢复
资源与效果的平衡是比较难达成平衡的,最理想的方案就是对于资源少的情况有一个低资源需求模型,对于资源多的情况只需要在后面堆叠模块就行。多阶段方案自然而然的就能实现了这个需求。结果如下表所示。
| Method | DeblurGAN-v2 | SRN | DMPHN | Suin | MPRNet(ours) | ||
|---|---|---|---|---|---|---|---|
| 1-stage | 2-stages | 3-stages | |||||
| PSNR | 29.55 | 30.10 | 31.20 | 31.85 | 30.43 | 31.81 | 32.66 |
| #Params(M) | 60.9 | 6.8 | 21.7 | 23.0 | 5.6 | 11.3 | 20.1 |
| Time(s) | 0.21 | 0.57 | 1.07 | 0.34 | 0.04 | 0.08 | 0.18 |
Section 6 结论
阿巴阿巴~