DAP: Detection-Aware Pre-training with Weak Supervision
🔗 PDF Link 🍺 Github Code
一个很朴素但有效的检测预训练方法
摘要
文章展示了一种检测感知的预训练方法(DAP),该方法在仅使用弱检测标签数据(如分类数据集Imagenet)来进行检测任务的预训练。与常用的检测任务通用的使用基于分类的预训练模型不一样的地方在于,我们使用了Class Activation Maps来转换分类标签为一个大致的位置标签,这使得预训练的过程能够感知到位置,同时预测边界框。实验结果显示,在下游的VOC/COCO检测任务中,DAP能够同时保证采样有效性和收敛速度。此外,当下游的检测任务数据集较小时能够较大幅度地提升性能。
主要流程图
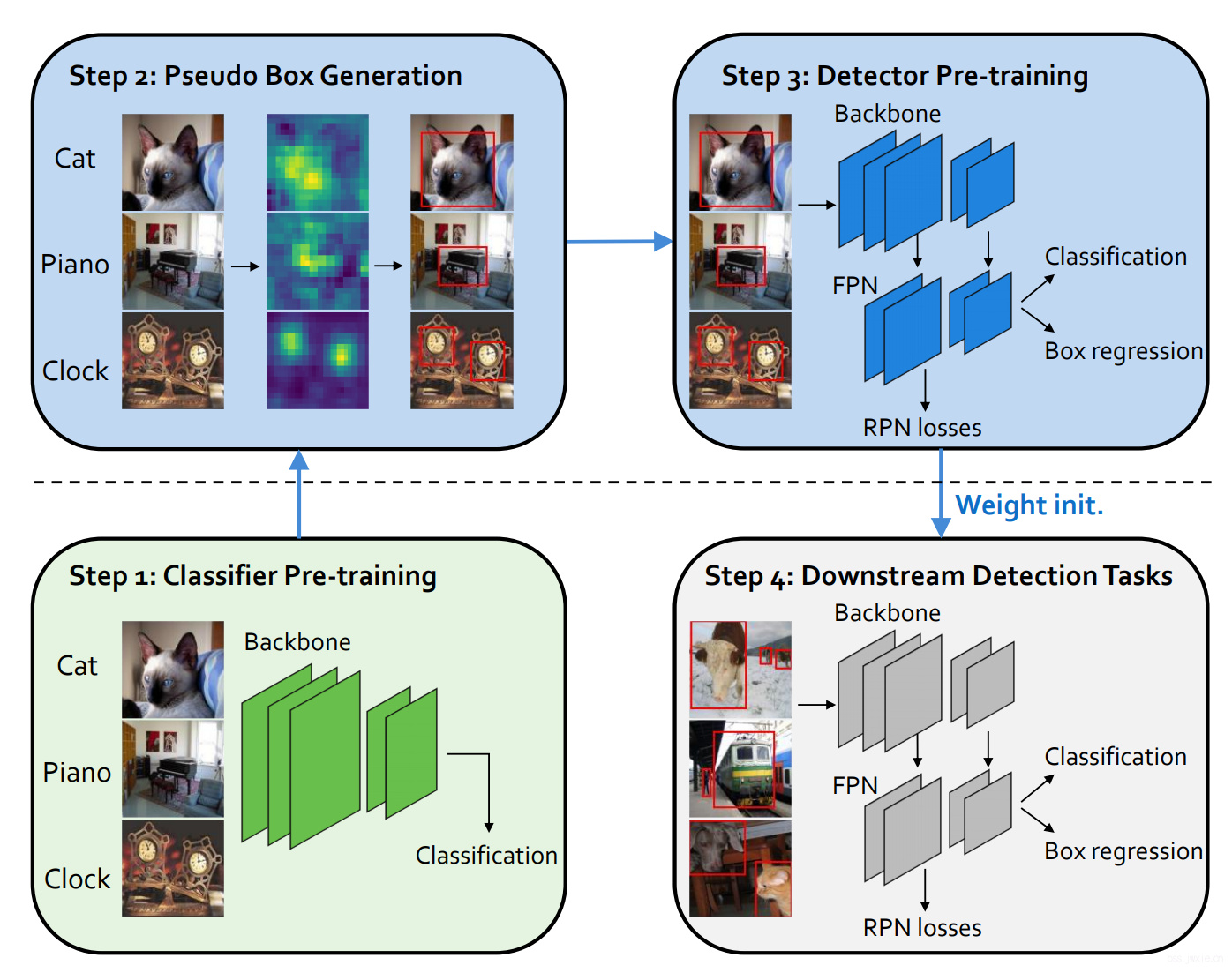
主要结果展示
表1 为COCO,表2为VOC07和VOC12

Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
稠密关系蒸馏与上下文感知聚合用于小样本对象检测,感觉也属于格式比较统一的一篇论文😂
摘要
传统的基于深度学习的目标检测方法训练需要大量的回归框的标注。小样本目标检测通过对旧类别的迁移实现新类别的检测具有较大挑战性,因为在小数据量的情况下细粒度的特征很容易数据不足而被忽略。本文提出了Dense Relation Distillation with Context-aware Aggregation(DCNet),旨在更完整地探索新的标签类别的特征以及捕捉query目标的细粒度特征。基于元学习框架,Dense Relation Distillation(稠密关系蒸馏)模块目标在于尽可能完整的提取support feature,确保其于query feature能够稠密匹配。辅助信息的大量使用使得模型能够应对许多具有挑战性的场景,如场景和外观的改变。此外,为了捕获更多对尺度敏感的特征,Context-aware Aggregation模块可以自适应不同的尺度。实验表明哦我们的方法取得了SOTA。
主要流程图
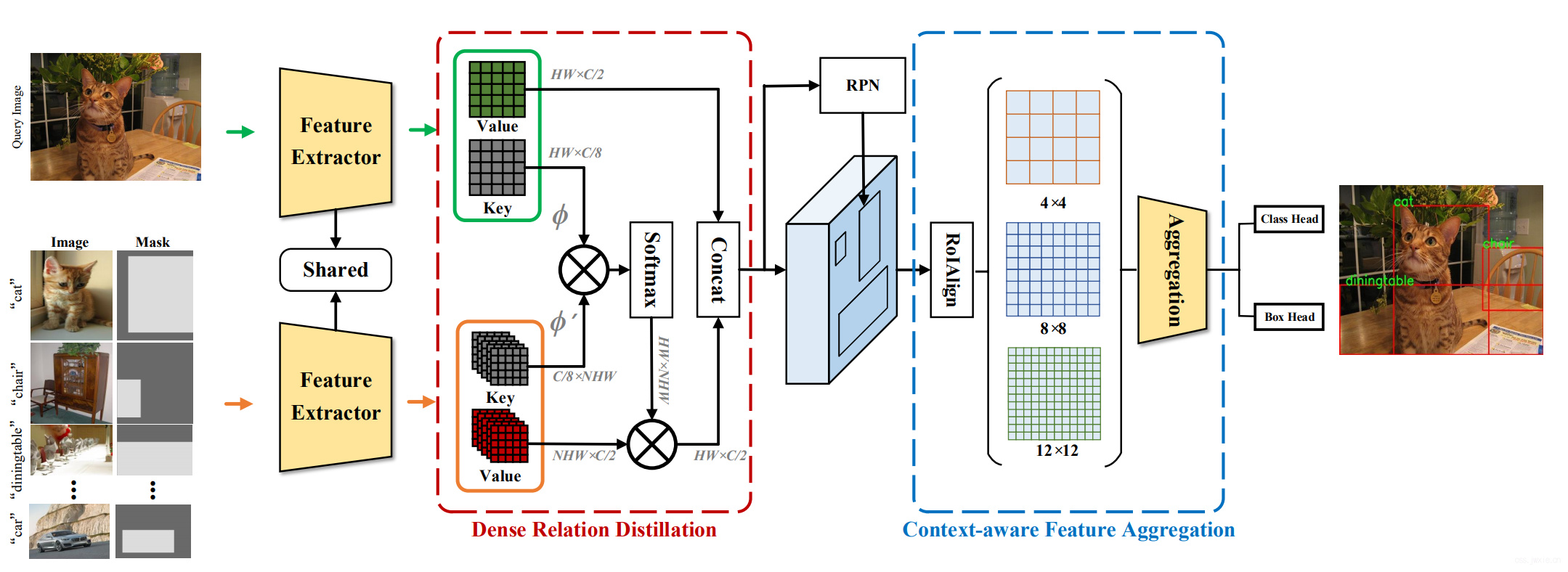
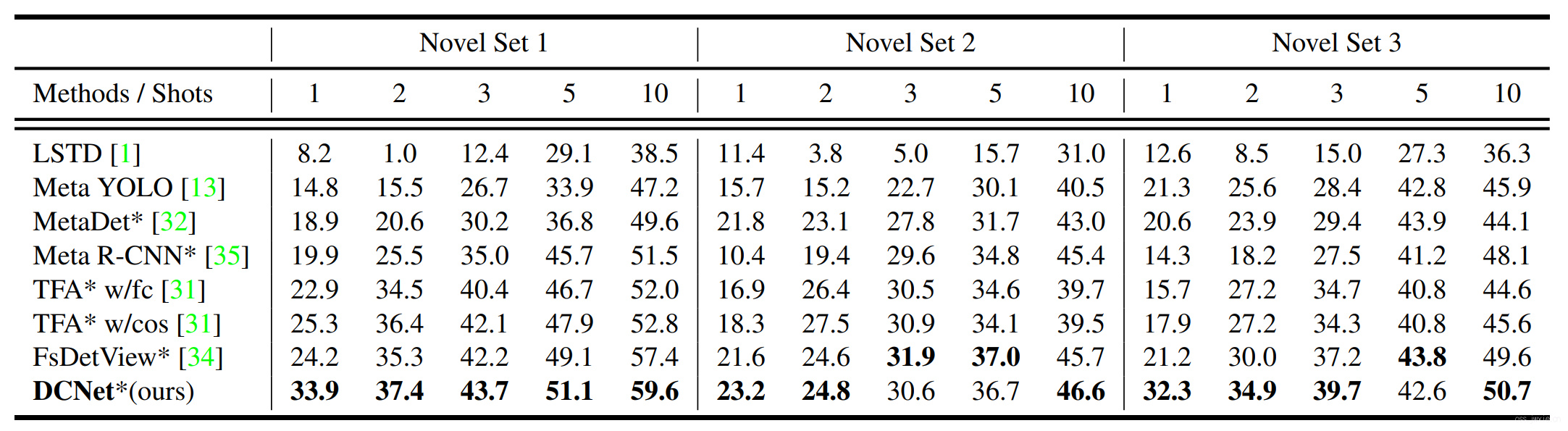
主要结果展示
VOC2007结果
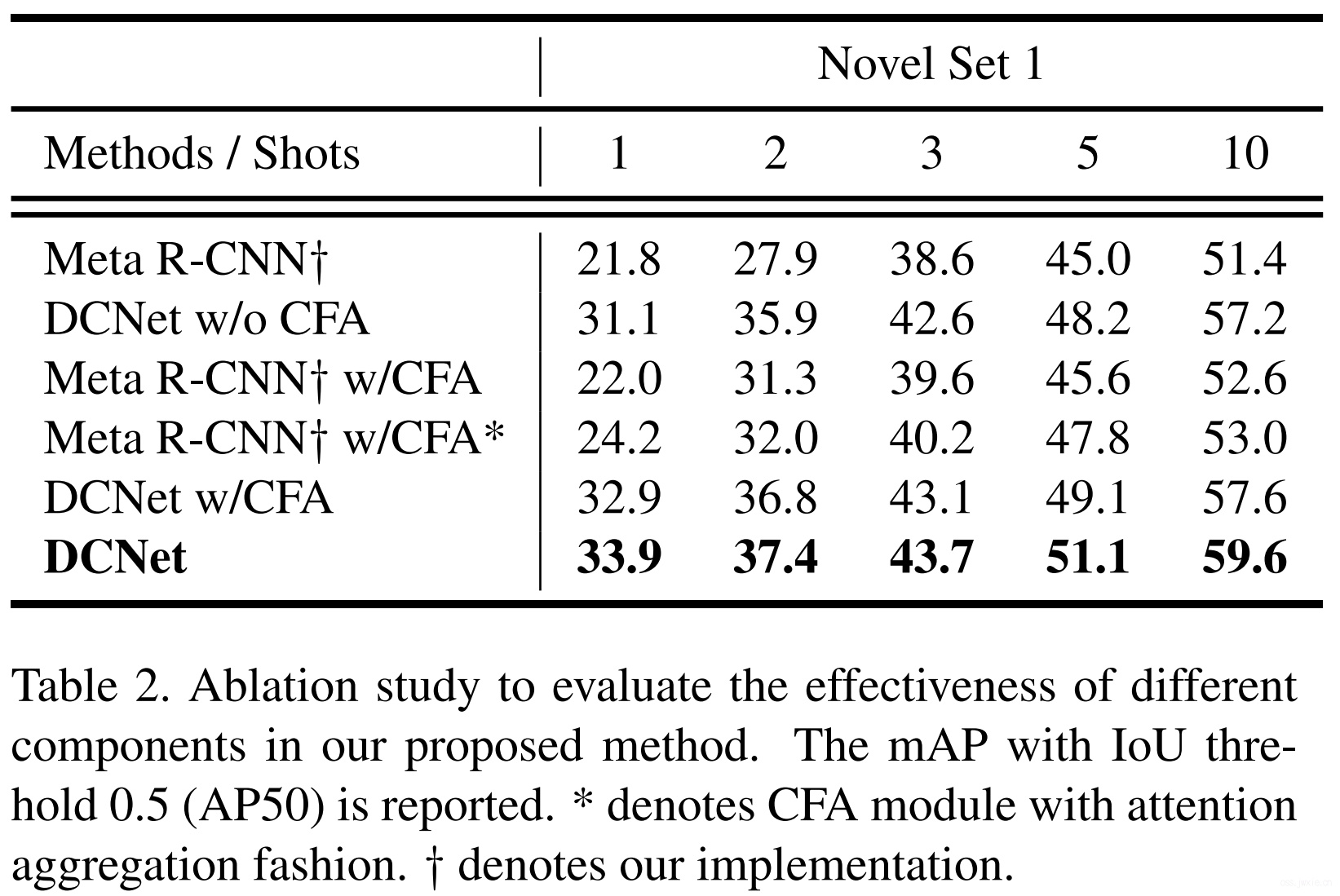
消融实验
Scale-aware Automatic Augmentation for Object Detection
尺度感知的自动目标检测数据增强方法
我本身不太关注这方面的内容,大致看了看感觉还挺有意思的…
摘要
本文提出了一种尺度感知的自动数据增强方法(Scale-aware AutoAug)。首先定义了一个新的尺度感知搜素空间,在这个空间里,为了保证尺度不变,设计了图片层级和回归框层级的增强方法。基于这个搜素空间,为了提高效率,我们提出了一个新的搜素方法Pareto Scale Balance。实验中,即使是对比大力度的多尺度训练baseline,Scale-aware AutoAug方法对例如RetinaNet, Faster R-CNN, Mask R-CNN, and FCOS均产生了显著、一致的性能改善。此外,该方法还可以被迁移到其他数据集以及基于box的任务中去以提升性能,例如实例分割,关键点估计。对比其他现有的自动化目标检测增强方法,该方法有着较少的计算负担。值得注意的是,我们搜索的策略提供了一种有价值的模式,这些模式直观地为数据增强设计提供了有价值的信息。
主要流程图

搜素算法,核心是联赛选择,具体看下图。

主要结果展示
不同检测框架以及其他的任务上的性能提升结果

You Only Look One-level Feature
摘要
本文重新探索了基于FPN的单阶段检测器,指出FPN的成功源自于将检测优化问题分而治之(divide-and-conquer),而不是单纯的多尺度特征融合(😂初看这个观点挺有意思哈)。从优化的角度看,我们引入了一个可替代的方案(只是用单层次的特征)来上述解决问题而不是采用复杂的特征金字塔。基于此,本文提出了You Only Look One-level Feature(YOLOF)。在该方法中,我们提出了有两个关键点,空洞编码(Dilated Encoder)以及 联合匹配(Uniform Matching),这两个部分的内容带来了一定的性能改善。在COCO上额外的实验证明了方法的有效性。YOLOF取得了与带有FPN的RetinaNet相似的性能表现,但是有着2.5x的速度加成。此外,没有transformer结构,以单阶层特征图的形式进行对比DETR,要比后者少训练7x的epoch数,但是最终性能却相当。对于608x608的数据输入,YOLOF取得了44.3mAP的性能表现,并在2080Ti上实现60FPS的预测,比YOLOV4快13%。
主要流程图
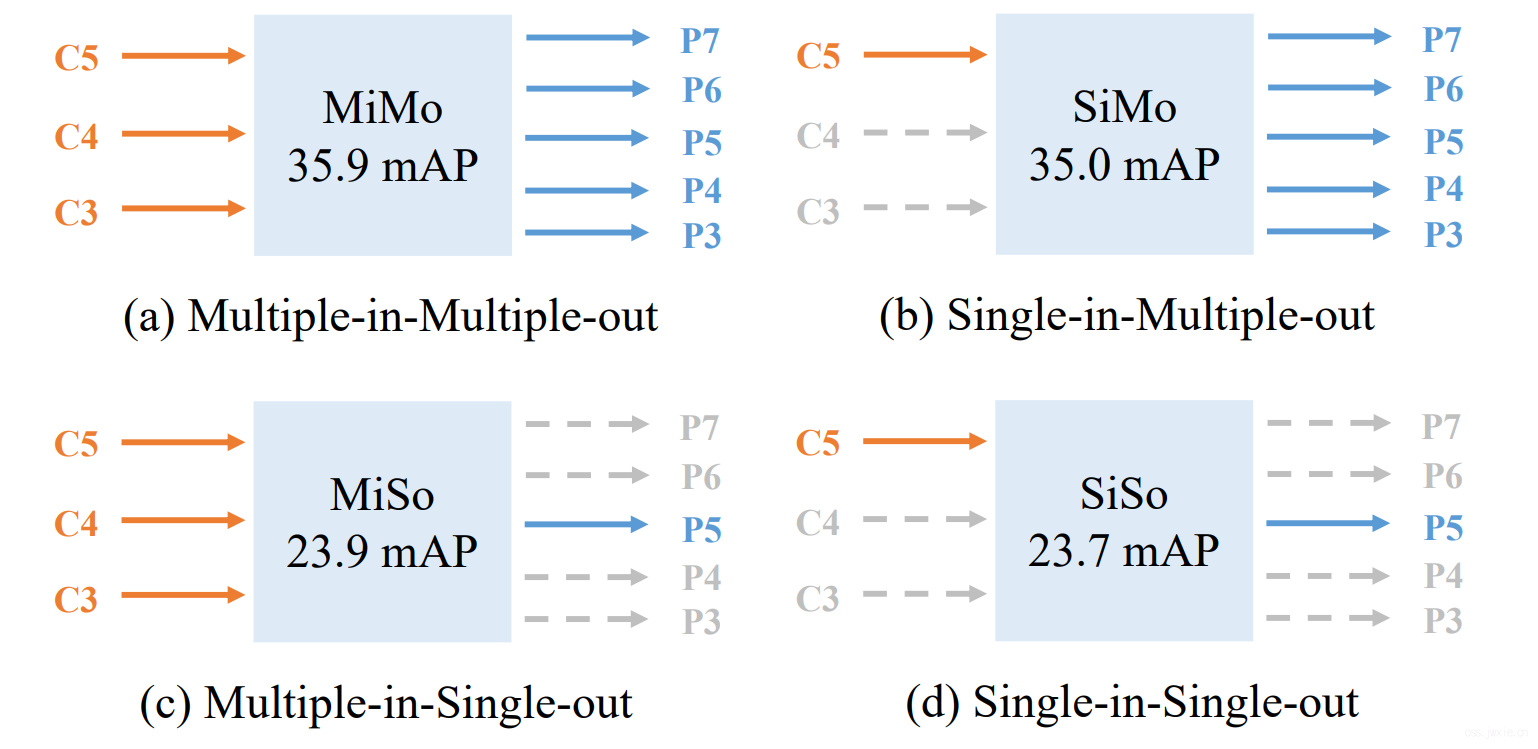
主要分成四个不同的形式,如上图。作者做了一些对比实验。发现在SiMo(单输入,不做特征融合)能和MiMo(例如FPN)的性能相当(性能差异小于1mAP)。但是MiSo和SiSo的差别很大,掉了12mAP。产生这样的结果有两个因素:
-
C5特征富含检测需要的不同尺度上的上下文信息,从而使得SiMo能够获得比较好的性能表现。
-
多尺度特征融合对比分而治之,后者更有益。
下图是主体结构,decoder部分负责分类、回归和生成最后的检测框。。

摘要中提到的空洞编码(Dilated Encoder)以及 联合匹配(Uniform Matching)两个方法各自用来解决,SiSo时特征的感受野不足和anchor box数量不足导致过于关注大目标的问题。
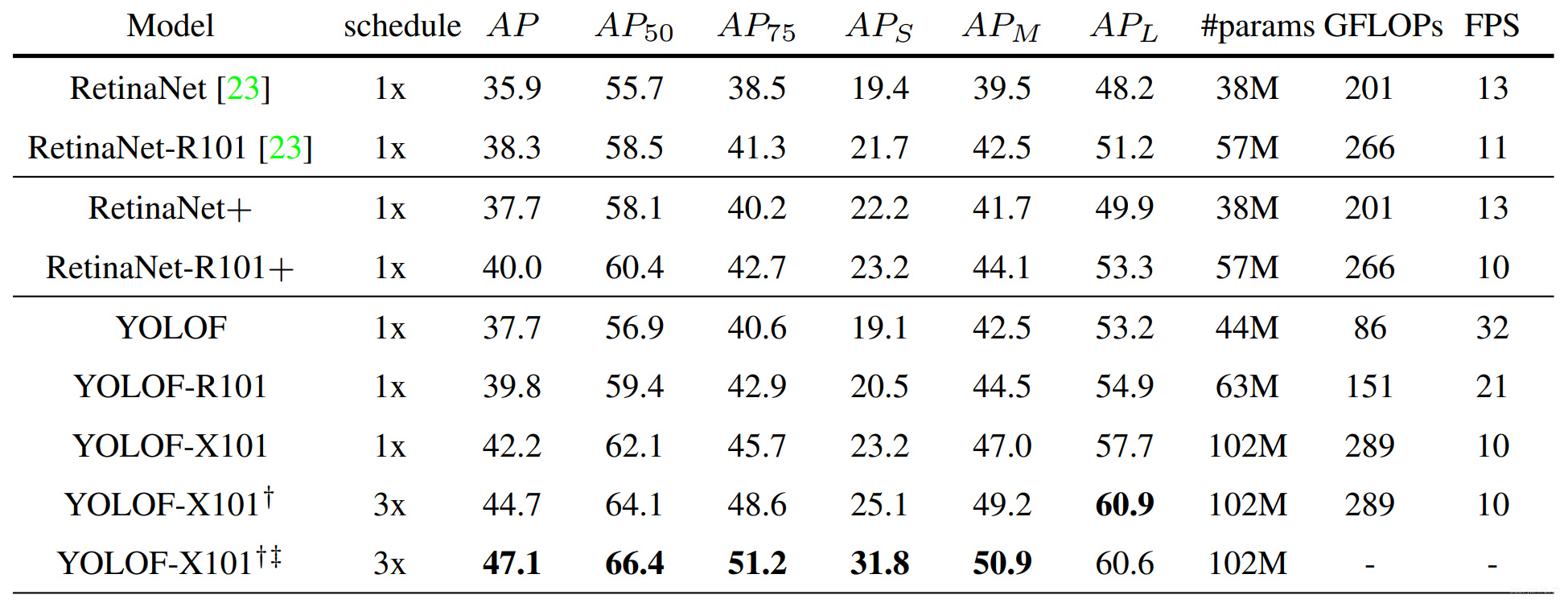
主要结果展示
小目标效果不如RetinaNet,大目标效果显著。
Multiresolution Knowledge Distillation for Anomaly Detection
🔗 PDF Link 🍺 Github Code
用于异常检测的多分辨率知识蒸馏
摘要
无监督表征学习已经被证明是异常检测的一个重要组成部分。主要的挑战有两个,首先是样本集数量可能通常不是很大,因此很难通过常规方法学习到泛化性较强的特征。此外,尽管在训练过程中只用正常图片,学到的特征却要能够足以判别正常与异常样本。本文提出了一种方案,对一个在ImageNet上预训练的专家网络的不同层的特征进行“蒸馏”,使之变为一个更简单的克隆网络来解决上述两个问题。在给定同一输入的前提下,通过比较克隆网络和专家网络中间激活值的差异,来实现检测和定位异常。我们发现,对比只使用最后一层的激活值的差异,考虑多个中间层可以更好地利用专家网络的知识,并提示更多独特的差异性。特别的,之前的方法几乎不是需要大量额外的基于区域的训练就是在异常定位的任务上效果很差。与之相反,我们的方法不需要任何特殊或者特意的训练过程,在我们新颖的异常区域定位框架中,还结合了可解释的算法。除了一些在一些测试数据集与ImageNet上取得了突出的对比结果,我们还在MNIST,F-MNIST,CIFAR-10,MVTecAD,Retinaal-OCT以及两个医疗数据集上的异常检测、定位任务上均与SOTA取得了有竞争力、显著的结果。
主要流程图
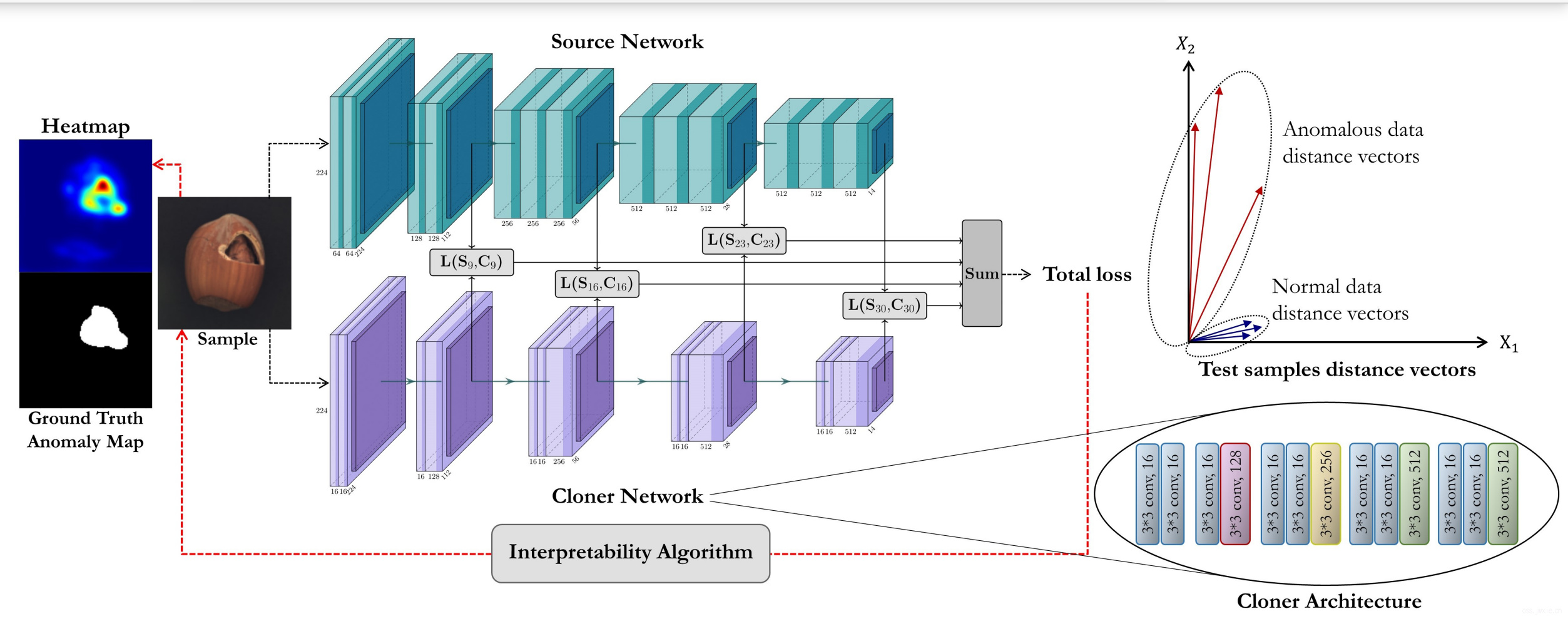
可视化算法使用的是基于梯度的方法,基于梯度来计算像素对梯度的贡献度,如下式。 $$ \Lambda=\frac{\partial \mathcal{L}_{\text {total }}}{\partial x} $$ 为了减少自然噪声,使用了高斯平滑和形态学开操作。 $$ \begin{aligned} M &=g_{\sigma}(\Lambda) \\ L_{m a p} &=(M \ominus B) \oplus B \end{aligned} $$
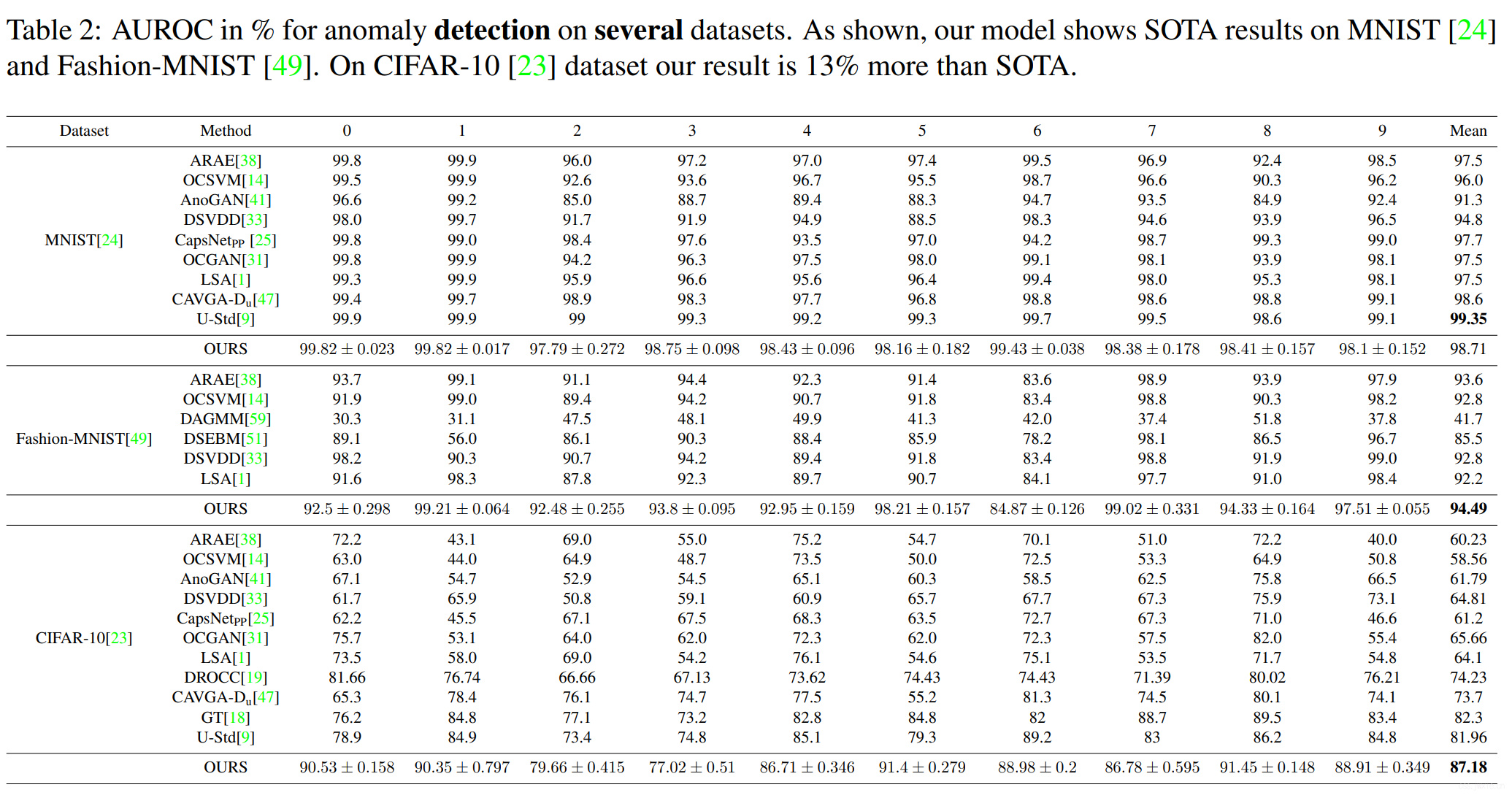
主要结果展示
HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens
🔗 PDF Link 🍺 Github Code
通过Hourglass(沙漏) Lens实现极快速NAS
摘要
NAS目的是自动地发现最优的模型结构。本文受hourglass的启发,提出了HourNAS方法,以实现极快速的NAS。这个方法启发源自于一个事实,网络结构的有效性往往取决于几个关键的blocks。DNN的关键模块就像是一个沙漏的那个狭窄的颈脖子,控制网络从输入到输出的路径,限制了信息流动并影响网络的准确性。其他blocks则占据了网络的主要体积,并确定了与沙漏上下两个类似灯泡的玩意儿,换句话说就是整体网络复杂度。为了在保证高准确率的同时实现极快的NAS,我们建议关注关键块的搜索,并保证这个模块搜索的优先性。我们还对于非关键块的搜索空间进一步压缩,只选择了在计算资源限制下,当前可负担的一些模块(❓这个看不懂),实验结果显示,使用GPU在ImageNet上,仅使用三个小时(约0.1天),我们的方法可以获得77%的top-1准确率,超越当前的SOTA。
主要流程图
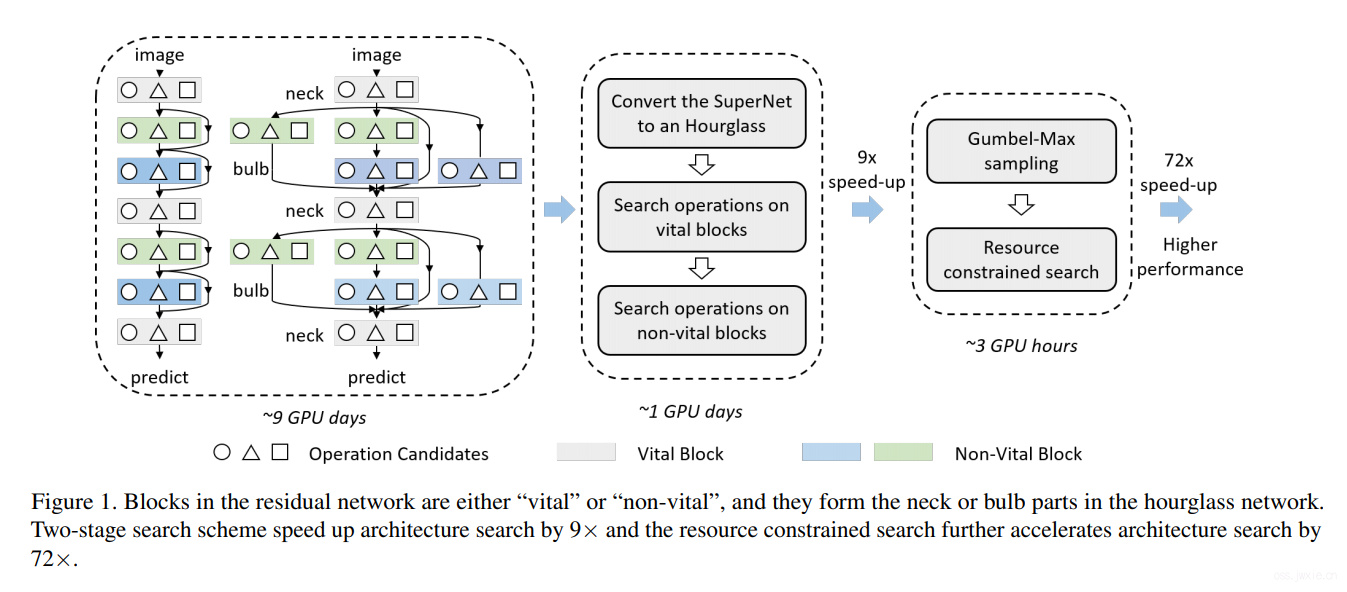
实际就是为什么会出现重要blocks和哪些blocks比较重要的问题。以resnet为例,从信息流动的角度来看,任何带skip的block实际只会有一半的贡献。而随着带有skip的模块越来越多,总的信息流动路径也越来越多,但是我有一些块是这些路径都必须经过的,比如说第一个卷积层,全连接层等,后者就是重要块。
然后问题就变成了怎么搜索的问题。分两阶段,贪心。先搜索重要的块,然后再确定重要块的条件的情况下去搜索非要重要块。
主要结果展示
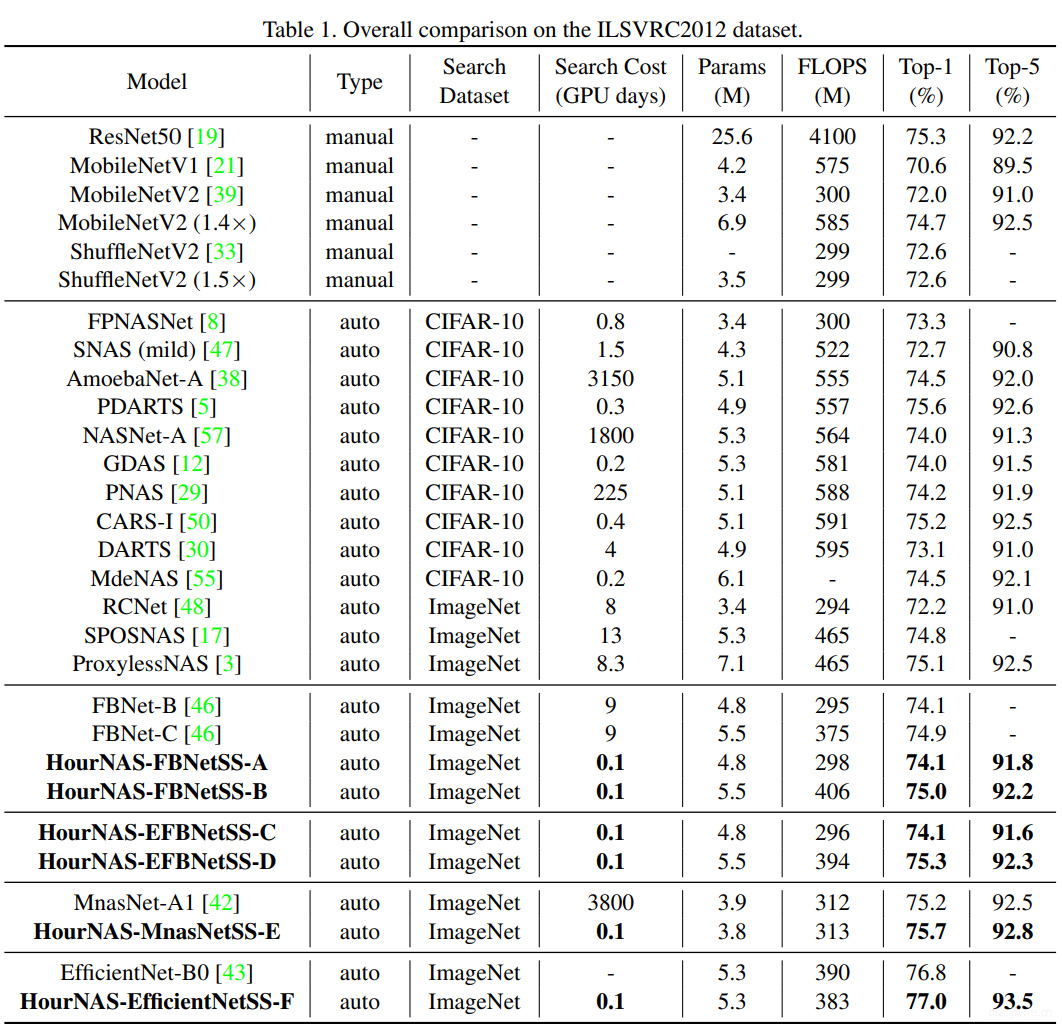
速度就是很快…