一些在论文阅读过程中看到的小知识
Making Convolutional Networks Shift-Invariant Again
- 问题 DNN的平移不变性实际上是MaxPooling带来的。实际上Maxplooing最大程度保留了高频特征,同时减少了网络特征的冗余(尤其是针对“有没有”和“是不是”的问题而言)。因此,这样会导致最终物体无论在图片的哪一个位置都可以被明确的保留下来。但是实验发现,Maxpooling虽然有这样的特性但是在实际运用的时候,移动一定的像素产生的结果却大不一样(❓为什么造成这个原因,没看明白)。
- 思路 保留的信息是否是过于高频的数据?或者说保留了过多的高频数据?因此,讲Maxpooling拆分成Max+Pooling两个部分,在中间添加模糊核,用以抑制高频特征。结果在很深的网络中有一定的缓释作用。
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
- 问题 CNN很难做到监督式的坐标渲染和分类,比如说把一个坐标变成一个点或者一个方块。同时,反过来看,把一个坐标转换成一个点(笛卡尔坐标系的x和y)也很困难。
- 思路 解决方案很简单,把x和y的坐标单独拉出来作为一个通道和正常的特征图concat起来可以有较好的性能提升。这个东西在检测(利好坐标生成)+生成(场景变换更平滑)方面有一定的应用价值,分类问题没有一个很好的应用思路。
Attentional Feature Fusion
- 问题 尽管在流行的深度网络中各种形式的特征融合曾不出穷,但是大多数的特征融合工作都专注于构建复杂的pathways,并使用一些简单的操作如加或级联,组合不同卷积核、不同组以及不同层之间的特征。但是问题是,这并不能给出一种对特征层进行线性整合的固定的方法,同时我们也完全不明确这种combination是否适合特定的对象。
SKNet和ResNeSt用了一些非线性的全连接来来给权重做融合,但也有不足的地方:
- 他们都只再同一层做了soft feature selecion,没有跨层。
- SKNet在特征融合的一开始使用了简单的Additon,但是这种简单的initial integration不太好,因为尺度和语义信息的level不是一致的。
- SKNet和ResNeSt都用了GAP来拿权重,但是这个方法太global,对小目标不友好。
- 思路
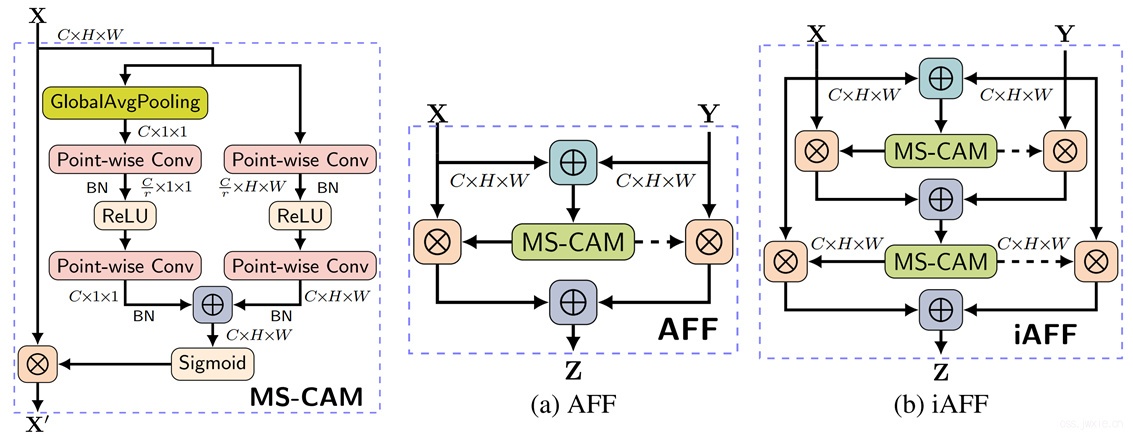
结构如下图所示
 一些常见的特征融合方式
一些常见的特征融合方式
 \(\mathbf M\)表示Multi-scale Channel Attention Module(MS-CAM)
\(\mathbf{Z}=\mathbf{M}(\mathbf{X} \forall \mathbf{Y}) \otimes \mathbf{X}+(1-\mathbf{M}(\mathbf{X} \forall \mathbf{Y})) \otimes \mathbf{Y}\)
\(\mathbf{X} \forall \mathbf{Y}=\mathbf{M}(\mathbf{X}+\mathbf{Y}) \otimes \mathbf{X}+(1-\mathbf{M}(\mathbf{X}+\mathbf{Y})) \otimes \mathbf{Y}\)
\(\mathbf M\)表示Multi-scale Channel Attention Module(MS-CAM)
\(\mathbf{Z}=\mathbf{M}(\mathbf{X} \forall \mathbf{Y}) \otimes \mathbf{X}+(1-\mathbf{M}(\mathbf{X} \forall \mathbf{Y})) \otimes \mathbf{Y}\)
\(\mathbf{X} \forall \mathbf{Y}=\mathbf{M}(\mathbf{X}+\mathbf{Y}) \otimes \mathbf{X}+(1-\mathbf{M}(\mathbf{X}+\mathbf{Y})) \otimes \mathbf{Y}\)