AnimeGAN a novel lightweight GAN for photo animation
🔗 PDF Link 🍺 Github Code
没研究过GAN,Github trends上瞅着个这个好玩的,跑个demo顺便瞅瞅论文,看有啥有意思的东西。
p.s. Date 20.07.22 GitHub好像近期有更新了,有AnimeGAN+了…
Section 1 简介
上来看到一句,咋这么像我们老板说的…
能说出这话说明这工作在当前来看的确没啥用了😂…
It not only allow the artists to focus on more creative work and save time, but also makes it easier for ordinary people to implement their own animation.
这不仅可以让动画原画家更加专注于创作更具创作性的内容并且缩短其创作时间,还可以使得普通人更有可能去实现自己的动画创意。
言归正传,GAN被广泛的用于style2style的图像迁移任务中,如CycleGAN和CartoonGAN。
但是目前存在三个缺点:
(1)生成的图像看不出有动画图像的那种纹理。
(2)生成图像丢失原始图像的部分信息。
(3)网络参数太多了,太吃显存(内存)。
AnimeGAN
- 参数少,引入了Gram matrix[1](大雾)来获得更多生动的动画图像。
- 使用了非成对数据,训练集的real-world图像集和anime图像集的内容不相关。
- 四个损失函数提升视觉效果,前两个损失函数是加在生成器上的,目的是使得生成图像有更动画化同时保留原图的色彩;第三个损失是加在判别器上的,目的是使得生成的图像拥有更生动的色彩;第四个损失也是在判别器上,保留清晰的边界。
- grayscale style loss
- color reconstruction loss
- grayscale adversarial loss
- edge-promoting adversarial loss[2]
- 使用了预训练的VGG19作为感知网络,并计算了生成图像与原图像的L1损失(称为感知特征)。目的是为了是生成图像获得更多原始图像内容细节。
- 为了使得训练更加方便和稳定,在生成器上加了一个预热训练。
论文章节描述
Section 2 Realted work
Section 3 Architecture
Section 4 Experiments
Section 5 Conclusion
Section 2 相关工作
⭐ 细节自己看奥 ⭐
- Neural style Transer
- Image2Image translation with GANs
Section 3
结构
总体结构是一个生成器G,一个判别器(废话😪),具体结构如下图
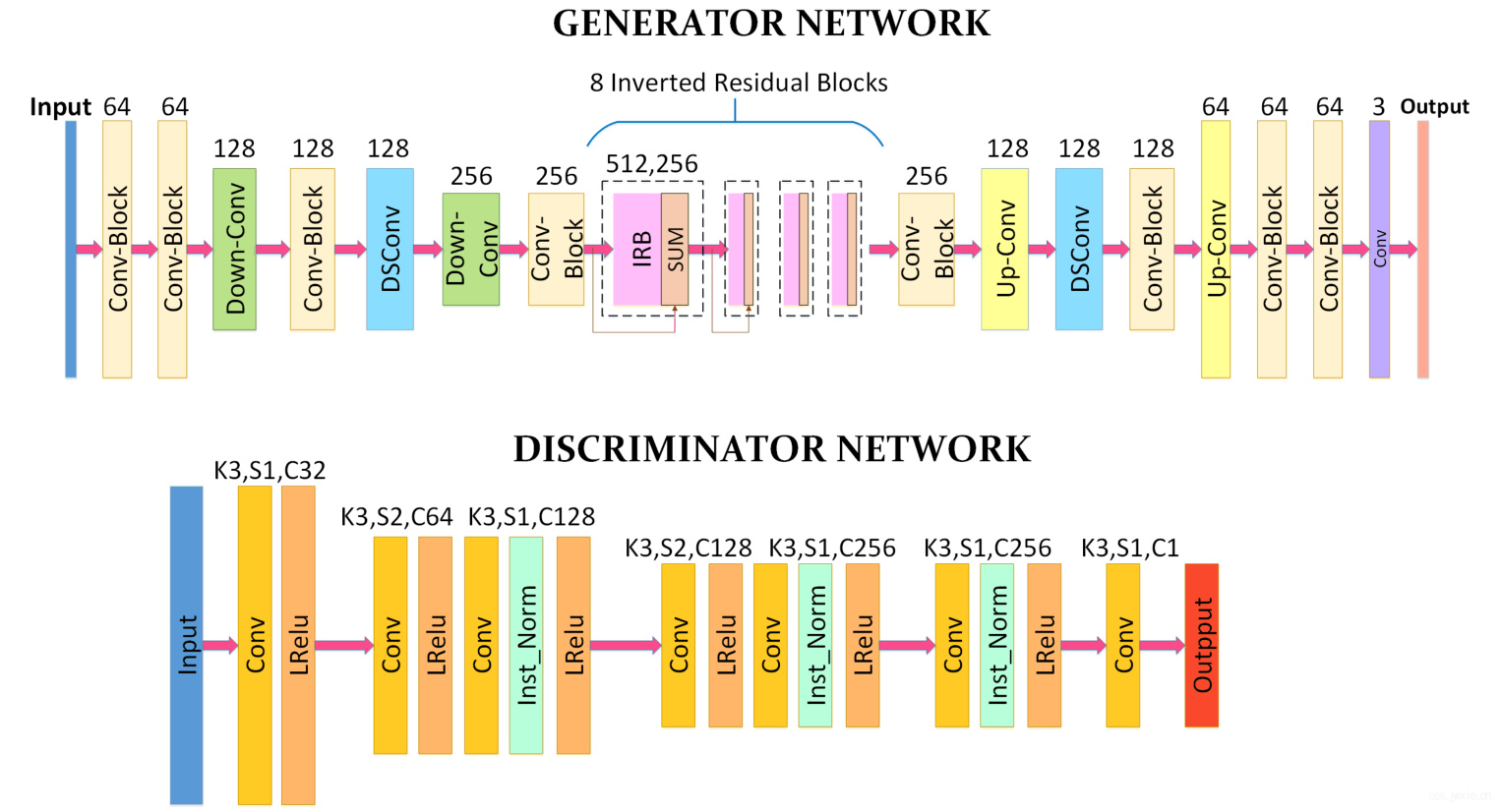
- G是一个对称编码解码结构,包含了传统卷积,深度可分离卷积,反转残差块(MobileNetv2里内个),上采样和下采样模块。其中最后一层由1x1卷积,不带Normalization层和一个tanh激活层组成。具体用到的各类卷积块的组成如下图所示。
- D用了和[2]一样的结构,用到了谱归一化使得训练更稳定。
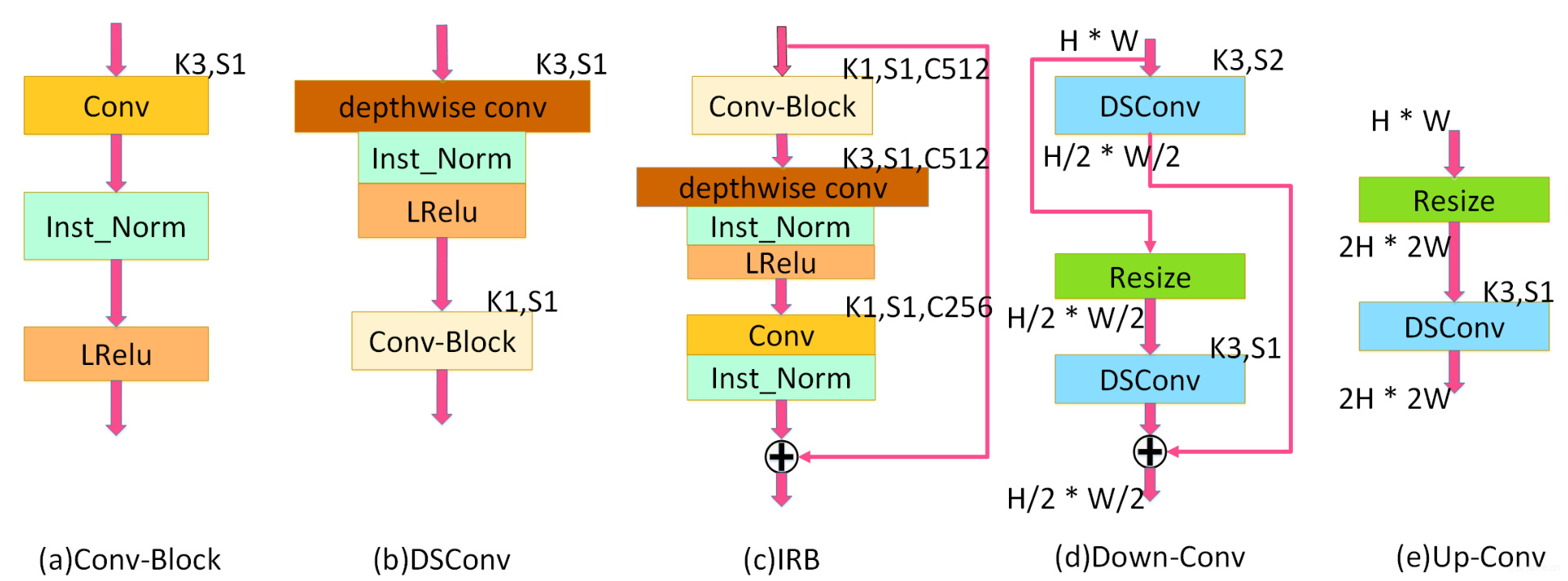
具体的,
- Conv-Block里,用了3x3卷积和Instance normalization(嘿,无知的我第一次见,背面经的时候还背到IN用在Style Transfer上)。
- DSConv里,用了3x3的深度可分离卷积,IN和LeakyReLU。
- IRB里,用了Conv-Block,深度可分离卷积,Pointwise卷积(嘿,又来一个没见过的)和IN。同时为了显著减少参数,G在中间使用了8个连续的IRB,其中每个IRB有3层,分别是512个PWConv,512个DW和256个PW。
- Down-Conv里,用了带步长为2和步长为1的的DSConv,避免采用max-pooling来降采样(会丢特征信息),这个模块的输出是DSConv-stride2和DSConv-stride1的输出的sum。
- Up-Conv里,2倍resize上采样,替代使用[2]里的0.5步长的卷积,因为会产生棋盘伪影(原来叫这个名字,学到老,活到老⭐)。
Loss函数 😎😎😎
定义
\(P\):真实图像域
\(A\):动画图像域
\(X\):灰阶动画图像域
\(E\):动画域去掉边界
\(Y\):灰阶动画域去掉边界
\(S_{data}(p) = {p_i | i = 1, … , N} \subset P\)
\(S_{data}(a) = {a_i | i = 1, … , M} \subset A\)
\(S_{data}(x) = {x_i | i = 1, … , M} \subset X\)
\(S_{data}(e) = {e_i | i = 1, … , M} \subset E\)
\(S_{data}(y) = {y_i | i = 1, … , M} \subset Y\)
这里讲明白了用Gram matrix是什么意思,这里并没有使用带颜色的\(A\)数据去训练,而是使用Gram matrix去使得生成的图像具有动画样式的那种纹理 –> 导致需要一种办法来生成Grayscale的\(A\)图像(以消除颜色干扰)也就是\(X\)。
总损失函数
$$L(G, D) = \omega_{adv}L_{adv}(G, D) + \omega_{con}L_{con}(G, D) + \omega_{gra}L_{gra}(G, D) + \omega_{col}L_{col}(G, D)$$
其中,
- \(L_{adv}(G, D)\)是Least Squares Loss,影响图像迁移部分
- \(L_{con}(G, D)\)是图像Content信息的loss,保证图像保留有原始图像的Content
- \(L_{gra}(G, D)\)是图像灰阶loss,使得图像中的线条和纹理保留有动画图像的样式
- \(L_{col}(G, D)\),由于使用上个那个loss会使得生成图像大概率变成灰阶图像,这个loss使得图像保留原始图像的色彩
- \(\omega_{adv}=300\), \(\omega_{con}=1.5\), \(\omega_{gra}=3\), \(\omega_{col}=10\)是权重超参数
对于\(L_{con}(G, D)\)以及\(L_{gra}(G, D)\),使用了VGG19作为感知网络来提取高层次的语义特征,具体的,
$$L_{con}(G, D) = E_{p_i \sim S_{data}(p) }[||VGG_l(p_i) - VGG_l(G(p_i)) ||1]$$
$$L{gra}(G, D) = E_{p_i \sim S_{data}(p) }, E_{x_i \sim S_{data}(x) }[|| Gram(VGG_l(G(p_i))) - Gram(VGG_l(x_i)) ||1]$$
下标\(l\)为VGG的层数,本文中采用的是"Conv4-4"层。
此外,为了使得颜色表征更加具体,使用了YUV颜色空间来构建\(L{col}(G, D)\),其中Y通道使用了L1Loss,UV两个通道则使用了HuberLoss,具体的,
$$L_{col}(G, D) = E_{p_i \sim S_{data}(p) }[||Y(G(p_i)) - Y(p_i) ||1 + ||U(G(p_i)) - U(p_i) ||H + \\ ||V(G(p_i)) - V(p_i) ||H]$$
最后,G的总损失可以看作为,
$$L(G) = \omega{adv}E{p_i \sim S{data}(p)}[(G(p_i) - 1)^2 +\omega_{con}L_{con}(G, D) + \\
\omega_{gra}L_{gra}(G, D) + \omega_{col}L_{col}(G, D)]$$
以及,D的总损失可以看作为,
$$L(D) = \omega_{adv}[E_{a_i \sim S_{data}(a)} [(D(a_i) - 1)^2] + E_{p_i\sim S_{data}(p)} [(D(G(p_i)))^2] +
\\ E_{x_i\sim S_{data}(x)}[(D(x_i))^2] + 0.1 \times E_{y_i \sim S_{data}(y)} [(D(y_i))^2]]$$
式中,\(E_{x_i \sim S_{data}(x)} [(D(x_i))^2]\)表示灰阶损失,\(0.1 \times E_{y_i \sim S_{data}(y)} [(D(y_i))^2]\) 表示物体边界损失,0.1是为了调节边界使得边界不那么锐利。
训练细节
- 预热训练G:一个epoch,lr=1e-4
- 正式训练G:lr=8e-5,D:lr=1.6e-5,epochs=100,batchsize=4,optimizer=Adam(total loss)
创新点
- 使用灰阶损失来优化生成图像纹理和线条。
- 使用颜色重构损失来保留原始图像中的色彩信息。
- 使用了色彩损失,避免了使用灰阶损失导致生成灰色图像。
- 俺们很快,比你们都快! ⭐⭐⭐⭐⭐
- 虽然快,而且还好评😏!
- 希望能在video上implement。
跑个Demo
开源代码基于TensorFlow1.8,我在跑Demo时候用的TensorFlow-1.13
|
|
Demo 1 - 风景园林:

Demo 2 - 水边:

Demo3 - 室内静物:

Demo 4 - 山水及远景人物:

Demo 5 - 人物:

Demo 6 - Anime 😏

ps: 真就是全员宫崎骏化呗 😂
Referenes
[1] Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., Yang, M.H.: Diversified texture synthesis with feed-forward networks. In: Proc. 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017. pp. 266–274. Honolulu, HI, United states (2017)
[2] Chen, Y., Lai, Y.K., Liu, Y.J.: Cartoongan: Generative adversarial networks for photo cartoonization. In: Proc. 31st Meeting of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2018. pp. 9465–9474. Salt Lake City, UT, United states (2018)